SpaceX Colossus1配22万颗GPU,算力领先性体现在哪里
2026年5月,AI公司Anthropic做了一笔“救命”的交易。它的王牌产品Claude大模型,因为算力不足,已经好几个月在高峰期对用户“限流”了。为了摆脱困境,它租下了埃隆·马斯克旗下SpaceX刚刚建成的Colossus1数据中心全部算力。
这笔交易的核心,是超过22万颗最新的英伟达GPU,以及支撑它们运行的300兆瓦电力。这相当于把一个中型城市几十万户家庭一年的总用电量,全部供给给这一个数据中心。
但问题来了:堆22万张顶级显卡,就能成为全球领先的AI算力中心吗?
不是堆显卡,是造一台“巨型计算机”
把22万颗GPU点亮,远不是插上电就能算。这就像把22万个最强大脑聚集在一起,目标不是让他们各自为战,而是让他们像一个人那样协同思考。
大脑间的“高速公路”:训练一个万亿参数的大模型时,超过一半的时间可能都花在GPU之间的“聊天”上。如果通信不畅,再强的单卡性能也会被浪费。Colossus1的解决方案,是在每台服务器内部,用英伟达的NVLink技术让GPU高速对话;在服务器之间,铺设英伟达InfiniBand高速网络,构建一个无阻塞的通信网络。这相当于给22万个大脑建立了毫秒级互通的超级城市供水网,信息流永不堵车。
给“高烧”的大脑物理降温:一颗H100 GPU满载时功耗约700瓦,22万颗就是154兆瓦的热量。传统风冷就像用电风扇吹,效率低且耗电巨大。Colossus1采用了液冷散热技术(冷板或浸没式),将冷却液直接引到芯片表面带走热量。这能将数据中心的能源效率指标PUE降至1.15左右,意味着每给计算设备供1度电,总耗电仅1.15度,而传统风冷数据中心这个数字通常在1.4以上。简单说,就是给高烧病人直接上冰毯,比吹空调管用得多,也省电得多。
所以,Colossus1的硬件领先,不是单卡参数的胜利(虽然它用的H100、H200都是顶级芯片),而是一场超大规模系统集成工程的胜利:它把22万颗“最强心脏”、一套“超级神经网”和一个“高效冷却系统”,整合成了一台能稳定运行的“巨型计算机”。
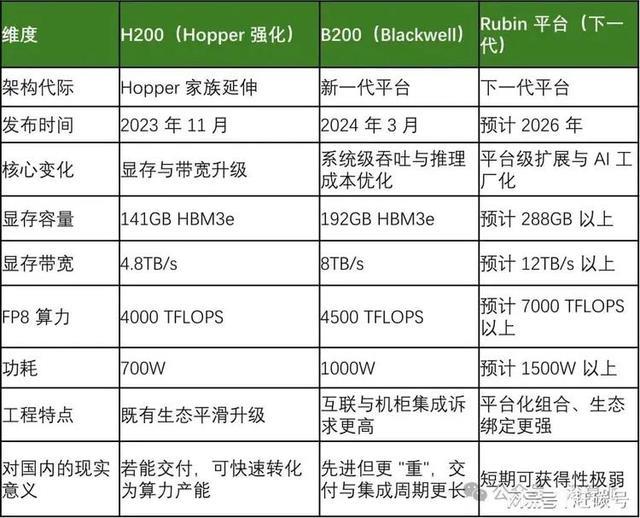
算力“硬通货”,一个中型城市的电力换来了什么?
投入一个城市的电力,产出的是实打实的计算能力。根据英伟达H100的官方参数(FP8算力4000 TFLOPS)估算,这22万颗GPU能提供约880 EFLOPS的FP8总算力。
这个数字可能有些抽象,但它的价值非常具体:它让Colossus1成为了全球规模最大的、可一次性调度的单一AI算力集群。
这是什么概念?对比一下同行:
OpenAI:拥有约15-20万张H100当量的算力,但分散在多个集群,无法一次性全部调用。Google DeepMind:约10-15万张H100当量。Meta:约8-10万张H100当量。这意味着,当Anthropic需要训练一个超大规模模型时,它可以独占Colossus1的全部22万颗GPU,获得连续、稳定的算力洪流。而其他公司可能需要在不同集群间调度、排队,甚至因为算力分散而无法启动某些超大任务。
这种一次性调度全球最大规模算力的能力,本身就是一种稀缺的、极具战略价值的技术领先。
从“模型竞赛”到“算力军火商”
Colossus1最深远的影响,可能不在于技术参数,而在于它改写了AI行业的游戏规则。
SpaceX将这座原本为自己AI业务(xAI)建造的算力堡垒,以每年约50亿美元的价格,租给了直接的竞争对手Anthropic。这标志着一个根本性转变:算力,正从AI公司私有的竞争壁垒,变成可以在市场上规模化流通的“硬通货”。
这背后是马斯克清晰的战略:短期,盘活闲置资产(原xAI算力利用率仅11%),获得巨额现金流;长期,SpaceX凭借其火箭发射和星链卫星网络的能力,正在布局更疯狂的“太空数据中心”计划——利用太空太阳能供电,借助接近绝对零度的宇宙环境进行天然辐射散热,从根本上突破地面数据中心面临的电力、土地和散热瓶颈。
因此,Colossus1的领先性,是三维的:
规模之最:全球最大的单一可调度GPU集群。效率之巅:顶级的液冷散热与高速互联技术,确保算力能被高效释放。战略之先:它不仅是计算设备,更是SpaceX从“火箭公司”转型为“算力基建军火商”的关键落子,将AI竞争从模型算法的单维比拼,拉入了算力基建、能源获取和太空布局的立体战争。当一家公司能像出售水电一样出售“算力”,并且开始谋划将数据中心建到太空时,它定义的已经不只是技术的上限,更是未来AI产业生态的形态。
大家都在看
-

【富矿精开】铜仁首宗含钾砂页岩探矿权成功出让 近日,铜仁市首宗含钾砂页岩探矿权——贵州省铜仁市万山区万山镇冷风硐含钾砂页岩矿探矿权顺利完成挂牌出让,由中盈华富(贵州)科技产业集团有限公司成功摘牌。此次出让标志着铜仁在含钾砂页岩资源“富矿精开”征程 ... 世界最长06-21
-

创新创造活力迸发 发展动能持续释放 ——宁德新能源新材料产业核心区建设提速坐落于福安湾坞半岛的青拓集团。郑霄 摄炎炎夏日,闽东大地上,比天气更加火热的是创新——采用宁德时代船用动力解决方案的全国首艘氢电拖轮投入使用,成为全国马力最大、锂 ... 世界最长06-21
-

澳大利亚野心勃勃,打造二战后最大舰队,欲成军事强国,恐难如愿 讲述国防故事,感受世界风云,分享军事科技,谢谢关注! 澳大利亚在大多数国人心目中,是个美丽富饶的国家,适合旅游,然而,近些年,随着澳大利亚被美收编,其想成为“印太地区”霸主的野心也逐渐显露出来。澳着手 ... 世界最长06-21
-

钱塘江畔的它,穿上了“铠甲”!家门口的亚运场馆,上“新”了 杭州奥体博览城内各大亚运场馆建设进度如何?有个亚运场馆特别醒目,仿佛“穿上”了铠甲,看上去相当炫酷。快来看看吧!“穿上”铠甲的亚运场馆长啥样?这些远看像铠甲的东西,覆盖在钱塘江南岸这座亚运场馆的顶部, ... 世界最长06-20
-
史诗级暴跌!原油创史上最大单日盘中跌幅,标普500期货一度“跌停” 每经记者:蔡鼎 每经编辑:叶峰北京时间周一早间,在石油输出国组织(OPEC)未能与产油国达成减产协议,导致沙特大幅下调油价后,国际油价开盘重挫30%。此前还有报道称沙特将提高石油产量,这也引发了对油价的全面担 ... 世界最长06-20
-

SpaceX Colossus1配22万颗GPU,算力领先性体现在哪里 2026年5月,AI公司Anthropic做了一笔“救命”的交易。它的王牌产品Claude大模型,因为算力不足,已经好几个月在高峰期对用户“限流”了。为了摆脱困境,它租下了埃隆·马斯克旗下SpaceX刚刚建成的Colossus1数据中心 ... 世界最长06-19
-

又下黑手!美国 FCC 直接禁了中国实验室,中方回应 无事生非!FCC 禁令背后的霸权逻辑2026 年 4 月 30 日,美国联邦通信委员会(FCC)全票通过一项提案,核心内容只有一个:全面禁止中国境内所有实验室,为进入美国市场的智能手机、电脑、摄像头等射频电子设备提供测 ... 世界最长06-18
-

世界防荒漠化日,人民日报讲了三个故事 来源:人民日报经济社会6月17日是世界防治荒漠化和干旱日。2023年6月6日,习近平总书记在加强荒漠化综合防治和推进“三北”等重点生态工程建设座谈会上指出:“打一场‘三北’工程攻坚战”,明确要求“努力创造新时代 ... 世界最长06-18
-

跨国车企在华故事翻开新一页 来源:人民日报海外版在位于江苏省南京市江宁开发区的长安马自达汽车有限公司总装车间内,工人在检测线上进行检测。新华社记者 李博摄2026第二十四届华中国际汽车展览会暨新能源·智能网联汽车展览会近日在湖北武汉国 ... 世界最长06-17
-

美媒直呼中国石油最大谜团,储量稳坐全球第一,却几乎从没动用过 前言最近美国多家媒体齐刷刷把目光对准了中国,还给中国石油储备安了个名号,全球能源市场“最大的谜团”。其实中国的战略石油储备并不是一开始就有的,上世纪七十年代西方闹石油危机的时候,中国还是石油出口国,大 ... 世界最长06-16
相关文章
- 中国最大安全套品牌,要被卖了
- 壮美峡谷!雅鲁藏布大峡谷,世界最深最长!震撼人心!
- 一束可吊一吨重物 沪研“大丝束”瞄准全球高端市场
- 联合国曾经警告:中国一旦人口迅速萎缩,将成为全球“最大挑战”
- 世界最大煤田真是植物形成的?煤层厚达1千米,哪里找这么多植物
- 2万亿美元,史上最大IPO敲钟了
- 煤层厚达1千米,绵延上千公里,世界最大煤田真的是植物形成的?
- 世界最大跨径钢拱桥 武两高速凤来大溪河特大桥钢混组合梁合龙
- 22公里山体被掏空 中国这条世界最长高速隧道 硬把7小时缩成20分钟
- 世界最大液氨运输船在沪交付,打造绿氨航运“中国方案”
- 2026北京车展炸场!全球最大规模,干货拉满
- 世界上只有中国广西才有的 "全球独一无二的 3 大奇景"
- 刷新全球纪录,世界最大27,1万立方米在沪开工,中国造船再攀高峰
- 世界最大轴对称太阳望远镜在稻城完成基墩封顶
- AI新入口?可能是这台AICUBE
- 藏在英伟达GPU背后的“电子工业大米”:MLCC的需求迎来重估
- 伊朗再袭以色列;全球首个“预制算力中心底座”投用丨盘前情报
- 煤层厚1千米、蔓延上千公里,世界最大煤田的成因是什么?
- 很多人都猜错了:世界上最早最长的写实小说,不是你猜的那几部!
- 陕西造全球最大2.4万吨自由锻造油压机投运
热门阅读
-
 1
世界上最长的性行为 07-14
1
世界上最长的性行为 07-14 -
 2
2
-
 3
3
-
 4
4
-
 5
5
-
 6
盘点一下世界之最,最长丁丁竟然有60㎝!! 04-20
6
盘点一下世界之最,最长丁丁竟然有60㎝!! 04-20 -
 7
7
-
 8
8