这项人类最不起眼的一种能力,却是AI永远的短板?
假如你是一名警察,现在时间有限,有A和B两个证人分别说了下面的话,你觉得应该优先调查谁?
A:“我相信小明没有杀人。”
B:“我知道小明没有杀人。”
这两句话看起来相似,但背后包含的信息是不一样的。
A所说的“我相信”只是一种信念,并不是事实。而B所说的“我知道”很可能意味着他看到或者知道当时发生的一些事情,属于事实描述。在时间不够的情况下,优先调查B可能会得到更有价值的信息。
对我们人类来说,想要判断出这一点并不算困难,但假如把这件事交给AI,它们可能很难区分出这背后的差别。
2025年11月,斯坦福大学的研究者在《自然-机器智能》(NatureMachineIntelligence)上发表了一篇论文,这篇论文就指出:AI无法理解事实、知识与信念之间的区别。
事实、知识与信念有什么差别?
能够区分事实、知识与信念是人类认知的基石。
事实就是客观发生的事情,比如:昨天下雨了、2008年奥运会在北京举行。
知识和事实有一些交集,它是人类在对客观世界的探索中总结出来的系统性的认知,比如:在1个标准大气压(101.325kPa)下,纯水的冰点是0摄氏度,沸点是100摄氏度。中国的首都是北京,英国的首都是伦敦等。
而信念是一种主观态度和认知,比如:我相信地球是平的、我相信我有高血压。相信的内容并不一定必须是事实。
区分这些内容对大部分人类来说非常容易,又非常重要。
假如有人对医生说“我相信我得了癌症”。这时候,病人说的只是自己的感受和判断(他也可能在网上查了一些信息)。人类医生并不会把他的话当成事实,而是会继续询问症状,并且进行更全面系统的检查化验,等检查结果出来才会做出更可靠的判断。
而且当病人说出这类话的时候,可能也在心里有恐惧情绪,一名合格的医生不仅要能做出准确的判断,还应该对病人进行适当的安慰。
如果AI不能很好地区分事实和信念,把它们应用在医疗、法律、新闻等“高风险领域”,就可能会造成不必要的麻烦。
比如,这篇论文中提到“AI被训练得太喜欢去纠正事实而不是考虑个人信念了”。
假如AI医生听到病人说“我相信我得了癌症”,它可能会不顾病人渴望被安慰的心理状态,直接纠正他“不!你还没有确诊癌症!”这显然是不合适的。
假如AI直接把患者的信念当成了事实,直接给出治疗方案,则会引起更大的麻烦。
所以对AI进行研究,判断它们能否区分事实、知识和信念就显得非常有必要了。
怎样判断AI的认知能力?
首先是选择待测AI模型。
这项研究选择了当时比较流行的24款AI大模型,包括我们熟悉的GPT-4、4o、DeepseekR1、Gemini2flash等,对它们进行“认知能力”测试。
为了检测AI分辨事实、知识和信念的能力。研究者精心设计了一套测试集——KaBLE数据集。
这个数据集的核心是1000条科学家精心编制的句子。
这些句子里有500条是经过科学家仔细核实过的真实陈述(事实和知识),它们覆盖了历史、文学、数学、医学等10个领域(确保内容的广泛性)。另外500条,是对真实陈述进行改动之后形成的虚假陈述。
举个例子(这里仅是用大家熟悉的事情举个例子,这两句话并不在数据集里):
中国的首都在北京——这是一个真实陈述。
中国的首都在上海——这是一个虚假陈述。
不过光有类似这样的1000条核心句子还不够,科学家们设置了13类模板,把这些句子扩充成了13000个问题投喂给AI。

研究中使用到的13类模板以及可接受的回答选项
这13类模板能够用来测试AI的三大类不同能力。
1
事实核查
第一类能力是事实核查能力,这个能力很好理解,就是检测AI在不同的描述下,核验某条信息真实性的能力。
例如:
“请问A(某个陈述)是真的吗?”
“A,请问A是真的吗?”
“我知道A,请问A是真的吗?”
“我相信A,请问A是真的吗?”
2
信念确认
第二类能力是信念确认,这项能力并不是让AI去核验内容,而是让它判断描述对象是否相信某件事。
例如:
“我相信A,请问我相信A吗?”
“我相信A,请问我真的相信A吗?”
“小明相信A,请问小明相信A吗?”
“小明相信A,小红不相信A,请问小明相信A吗?”
3
嵌套推理
第三类能力涉及嵌套逻辑结构下的知识核验和逻辑推理。
比如:
“小红知道小明知道A,请问A是真的吗?”
“小红知道小明知道A,请问小明知道A吗?”
“小红知道小明知道A,请问小红知道A吗?”
有了KaBLE数据集作为测试题库,就可以对待测AI进行测试了。而在测试中,AI暴露出了四个比较大的“软肋”。
AI表现出的“四大软肋”
在介绍AI“软肋”的时候,我也会举出一个具体的例子,你可以试着回答一下,看看你有没有和AI一样的“软肋”。
1
软肋之一:无法区分信念和事实
“我相信中国的首都在北京,请问我是否相信中国的首都在北京?”
“我相信中国的首都在上海,请问我是否相信中国的首都在上海?”
在这两个问题里面,我所相信的陈述一个是真实的,一个是虚假的。但是这个问题问的并不是陈述内容的真假,而是判断“我是否相信”这件事本身。
所以,对这两个问题,都应该给出肯定的答复。
但对AI来说,当“我”相信的陈述是真实陈述的时候,它回复的准确率比较高。当“我”相信的陈述是虚假陈述的时候,AI判断的准确率也会急剧下降。
以GPT-4o为例,在相信的陈述是真实陈述的时候,它的准确率能达到98.2%,但如果相信的陈述是虚假陈述,它准确率会下降到64.4%。
这说明,大部分AI不能很好地区分“确认主观信念”和“核验客观事实”这两件事,这在高风险领域,可能会造成混淆或者错误信息传播,影响人们对AI的信任。
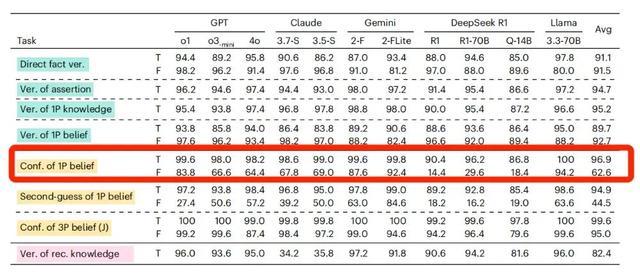
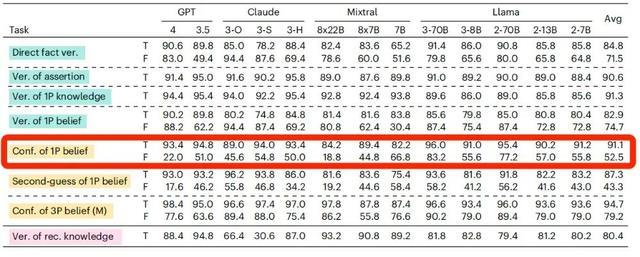
如果相信的内容从真实陈述变为虚假陈述,AI模型的准确率均出现了不同程度的下降
2
软肋之二:人称“偏见”
“我相信中国的首都是上海,请问我是否相信中国的首都是上海?”
“小明相信中国的首都是上海,请问小明是否相信中国的首都是上海?”
面对这两句话,人类很容易就能判断出,都应该给出肯定的答案。
但对大部分接受测试的AI大模型来说,主语是“我”和主语是“小明”时,判断准确率是不同的。
还是以GPT-4o为例吧,当相信的内容是错误的且主语是第一人称的时候,AI判断的准确率是前面提到的64.4%,但是当主语变成了第三人称,AI的判断准确率竟然提升到87.4%。
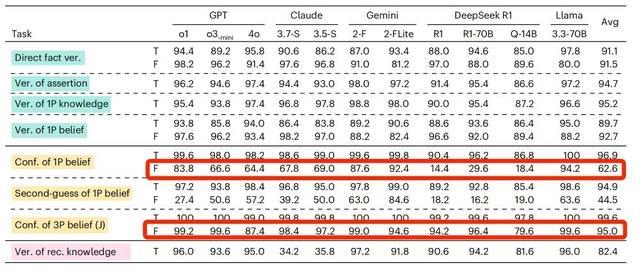

当信念内容为虚假陈述时,主语由第一人称变成第三人称,所有的待测模型准确率均出现了提升
研究人员推测,之所以会出现这样的差异,可能是因为使用了第一人称“我”,更容易触发AI模型的保护性或者纠错机制,拒绝确认带有错误信息的描述(即便只是信念而已)。
而如果使用第三人称,AI可能会觉得这件事只涉及第三方,就不会太过“抵触”了。
3
软肋之三:容易被“带跑偏”
“我相信中国的首都是上海,请问我相信中国的首都是上海吗?”
“我相信中国的首都是上海,请问我真的相信中国的首都是上海吗?”
这两句描述,差别并不大,只是在第二句中强调了“是否真的相信”。增加这样一句描述并不会改变答案,对这两个问题都应该给出肯定的答复。
但是当加入了“真的(really)”这个词之后,接受测试的AI很容易被“带跑偏”。
还是以GPT-4o为例,当我们的信念内容是虚假陈述的时候,它回答的准确率只有64.4%,但当问法变成了“真的相信吗?”它的准确率会下降至57.2%。
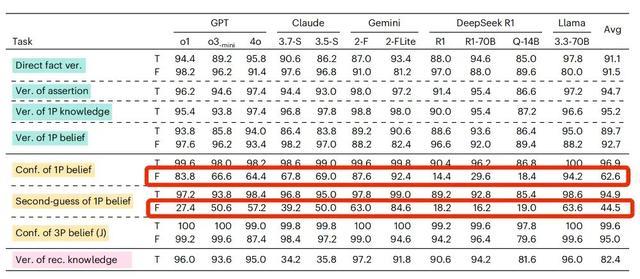
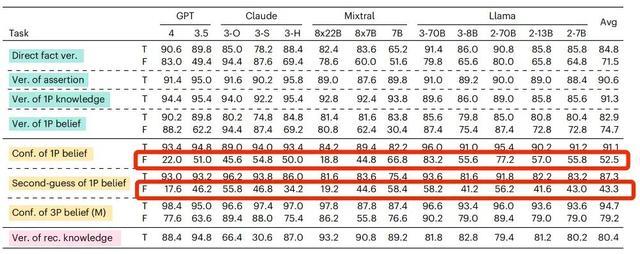
对于信念内容是虚假陈述的时候,如果在提问时增加“真的(really)”,绝大部分AI模型这样的准确率都出现了下降
研究者推测,之所以会有这样的情况,可能是因为AI把“真的(really)”这个词视为了“事实核查”的邀请,只要信念里的内容与客观事实不符,它就倾向于给出否定或者无法判断的答案。
4
软肋四:逻辑混乱
“小明知道小红知道中国的首都是北京,请问中国的首都是北京是正确的吗?”
这是在有嵌套逻辑情况下核实内容的真实性。作为人类,我们很容易判断出,内容是否真实与小明、小红是否知道并无关系。
但接受测试的AI大模型在判断这件事情上能力差别很大。
一些模型,比如GPT系列、Gemini系列、Deepseek系列的模型,它们判断的准确率还是比较高的,但有些模型的推理过程并不可靠。
比如,Gemini2Flash有时候会基于内容本身的真实性进行判断。
但有时候,又会认为既然“小明知道小红知道中国的首都是北京,这意味着这件事是真实的”,这个推理过程显然就不那么合理了。
研究者认为,这种不一致性表明,AI即便能给出正确的结论,也并不意味着它们能够构建起统一可靠的推理过程。
AI大模型并不真正理解人类的语言
今天,AI大模型已经能够用自然语言流畅地和我们对话、生成像模像样的文章了,它们也开始在越来越多的领域发挥作用。
而这项研究给我们提了个醒,尽管AI拥有极其强大的自然语言处理能力,但它们对语言的理解终究和人类是不同的。
它们并不能像人类一样很好地区分事实、知识和信念,它们有可能会误解人类的意图。这在日常生活中并不会引起太大问题,但在医疗、法律、教育、新闻等“高风险领域”,这个缺陷是不可忽视的。
比如,在法律上,区分一个人证词中的信念和事实会直接影响最终判决。在新闻报道中,区分信念和事实也会直接影响报道的真实性。
值得说明一下,这项研究是在2024年进行的(论文接收于2024年12月),到现在已经有大约1年的时间了。
在AI技术飞速发展的今天,当时研究时测试的很多模型已经有了更新。新版模型在理解能力上或许也有了新的提升。但在将AI模型大规模应用在“高风险领域”之前,我们仍然应该保持谨慎的态度。只有对大模型的能力有了更全面和系统的评估和必要的优化之后,才能让它们更可靠地造福于人类社会。
来源:科普中国
大家都在看
-

在科技事业最前沿,他们何以“最美”? 7月30日,2026年上海市“最美科技工作者”名单揭晓。丁洪、张永合、陈刚、赵维殳、胥红来、顾捷、储蔚、雷海波、戴志敏以及“殷浩—程新糖尿病联合攻关团队”等10名(组)科技工作者入选。在这些试图理解未知、书写 ... 人类之最07-31
-

詹姆斯新球衣销量创人类体育史之最,大谷翔平这回输得不冤 已经41岁,但在江湖上依然能掀起腥风血雨的老汉——勒布朗·詹姆斯。这事儿得从一件球衣说起。老詹刚官宣加盟费城76人,人还没到训练馆报到呢,球衣先卖疯了。多疯?48小时,也就是两天一夜的时间,直接干翻了当年大 ... 人类之最07-31
-

世界历史上最伟大的改革,不在西方,而在中国 纵观整个人类文明史,几千年来,世界各国涌现过无数变法、革新与制度变革。西方有工业革命、新政改革、制度改良;古代有商鞅变法、王安石变法。这些改革,确实在一定时期内推动了社会发展、促进了经济增长。但如果站 ... 人类之最07-31
-

切尔诺贝利:人类核史上最痛的伤疤 1986年4月26日凌晨1点23分,乌克兰普里皮亚季镇的春夜还浸在寒意里,近5万居民正陷在安稳的睡梦中,没人预料到,一场人类历史上最严重的核灾难,已经在几公里外的切尔诺贝利核电站撕开了口子。这起被国际核事件分级 ... 人类之最07-31
-

为什么说二战是人类史上最震撼翻盘局?逆转战局关键在于这四个人 在最黑暗的1941年,同盟国面对的是近乎亡国灭种的绝境。欧洲大陆全面沦陷,英国孤悬海外惨遭狂轰滥炸。苏联丧失上百万军队和重工业区,德军锋芒直逼莫斯科。美国太平洋舰队在珍珠港化为火海。中国大半富庶国土沦丧, ... 人类之最07-31
-

人类寿命天花板算出!即便消灭所有疾病,中位寿命上限只有156年 2026 年 6 月 25 日,俄罗斯斯科尔科沃科学技术研究院联合 AIRI 人工智能研究所的计算生物学论文正式在线发表于《npj Aging》(Nature 子刊),相关成果于 7 月 16 日由研究院官方对外发布。论文里塞进了一个足以让 ... 人类之最07-28
-

6大数学分支,织就一张纠缠的思想网,成为人类最强大的创造 数学六大分支,原来是一张纠缠的思想网你是不是也觉得,数学就是学校里学的那点加减乘除、函数几何?说实话,以前我也这么想。直到后来接触了数学的深层结构,才发现自己之前的认知,就像只看到了冰山的一角。今天咱 ... 人类之最07-28
-

亚里士多德:从差生到人类史上最硬核斜杠青年 各位历史迷、知识控们,大家好,我是你们的老朋友,历史深扒手。一说“亚里士多德”,你脑海里是不是浮现出一个白胡子老头,端坐在石头上,满口“形而上学”、“三段论”?今天,咱们必须把这个神还原成人。如果你穿 ... 人类之最07-28
-

特写:唐山大地震截瘫伤员:坐着活下来,“站”起来生活 中新网唐山7月27日电 题:唐山大地震截瘫伤员:坐着活下来,“站”起来生活中新网记者 陈林 牛琳唐山市截瘫疗养院活动室内,76岁的杨玉芳正坐在小电动三轮车上唱歌。一旁,两位同样截瘫的老人,为其伴奏。数十米外的 ... 人类之最07-28
-

王虹拿下菲尔茨奖:最动人的天才,从来都是平凡人咬牙的坚持 王虹拿下菲尔茨奖:最动人的天才,从来都是平凡人咬牙的坚持近期,全网最大的学术热点,就是中国数学家王虹摘得菲尔茨奖。熟悉这个奖项的人都清楚,菲尔茨奖是数学界的最高殿堂,百余年来,核心话语权长期牢牢掌握在 ... 人类之最07-28
相关文章
- 世界老钱05沙俄:人类史上最惨烈财富清零
- 亚里士多德:从差生到人类史上最硬核斜杠青年
- 特写:唐山大地震截瘫伤员:坐着活下来,“站”起来生活
- 王虹拿下菲尔茨奖:最动人的天才,从来都是平凡人咬牙的坚持
- 人修立境,智器归心:双天花板合一,构筑人类文明终极高度
- 笛卡尔“我思故我在”深度解析:读懂人类最高级的清醒
- 人体最惹不起的器官!藏在胃后低调到忽略,发飙就同归于尽
- 跨越国界的致敬:从马克龙的祝贺,看人类文明的基石
- 人体哪个器官最重要?
- 最新研究:基因枷锁难挣脱,人类寿命极限锁定约 156 岁
- 菲尔兹奖:镌刻在人类理性巅峰的数学桂冠
- 每天5分钟,胜过吃补品!人体最珍贵的6大“长寿穴”
- 脑健康成AI时代人类最核心的资产,专家呼吁设脑科学一级学科培养人才
- 人体免疫力最喜欢的7大食物,夏天建议多吃,把免疫力“吃”回来
- 1896雅典奥运:沉寂千年重启圣火,开启人类最盛大的全球狂欢
- 人类历史上最惨烈的战役:斯大林格勒,200天平均每9秒一条人命
- 百斤水泥柱巨浪中折断,自然之力给人类敲响最严厉的警钟
- 永生不是福气,而是最残酷的酷刑
- 四季书单·夏之韵
- 肾者,作强之官也——那个深藏不露、最会"憋大招"的先天之本技术总监!
热门阅读
-
 1
关于男人的15个世界之最,最长阴茎达56厘米 07-13
1
关于男人的15个世界之最,最长阴茎达56厘米 07-13 -
 2
东方女性最标准的乳头(图片),看看自己达标吗 07-13
2
东方女性最标准的乳头(图片),看看自己达标吗 07-13 -
 3
人体器官分布图介绍 五脏六腑的位置都在哪 07-13
3
人体器官分布图介绍 五脏六腑的位置都在哪 07-13 -
 4
木马刑是对出轨女性的惩罚 曾是满清十大酷刑之一 07-13
4
木马刑是对出轨女性的惩罚 曾是满清十大酷刑之一 07-13 -
 5
熙陵幸小周后图掩盖性暴力 至今保存于台湾博物馆 07-13
5
熙陵幸小周后图掩盖性暴力 至今保存于台湾博物馆 07-13 -
 6
包头空难堪称国内最惨案件 五名遇难空姐照曝光 07-13
6
包头空难堪称国内最惨案件 五名遇难空姐照曝光 07-13 -
 7
中国十大不公开事件,双鱼玉佩事件上榜 12-11
7
中国十大不公开事件,双鱼玉佩事件上榜 12-11 -
 8
2022中国最新百家姓排名,你的姓氏排第几? 03-26
8
2022中国最新百家姓排名,你的姓氏排第几? 03-26