谷歌HOPE架构来了!突破大模型长期记忆难题,智能体要爆发?
日前,Google在其发布的论文《Nested Learning: The Illusion of Deep Learning Architectures》中,提出了一个名为 HOPE 的新框架试图解决大模型长期记忆的问题。
这一架构备受关注,因为长期记忆一直困扰着大模型的发展,甚至影响着AI落地到智能体的广度与深度。
今天让 AI 写一段漂亮的回答不难,难的是隔了一周、换了工作任务,它还记得你之前某次对话的关键细节,不断更新对你的个性化记忆。也只有在这一刻,大模型才真正开始接近「持续工作的智能体」,而不是一次性消耗品。
可以说,大模型的「短期能力」决定了它能不能把一句话说通,但长期记忆真正决定的,其实是它有没有资格被称为「助手」。
也正是因为这一点,去年最后一天谷歌研究团队提出的 Titans 架构,在 2025 年被反复翻出来讨论,并不意外。这篇论文试图回答的,并不是「上下文还能拉多长」这种老问题,而是一个更本质的命题:
当注意力只是短期记忆,大模型到底该如何拥有真正的长期记忆。

图片来源:谷歌
在 Titans 里,Transformer 的 self-attention(自注意力机制)被明确界定为「短期系统」,而一个独立的神经长期记忆模块,负责跨越上下文窗口、选择性地存储和调用关键信息。这套思路,几乎重新定义了大模型的「大脑结构」。
现在回头这一年,从谷歌 Titans 到字节 MemAgent,再到谷歌 Hope 架构,大模型的长期记忆真正有了突破。
过去一年,不论是谷歌在此基础上延展出的多时间尺度记忆体系,还是行业里围绕超长上下文、智能体(Agent)记忆、外部记忆中台展开的密集探索,都指向同一个趋势:长期记忆,正在从工程补丁,变成大模型能力的核心坐标轴。
模型不再只比谁的窗口更长、参数更多,而是开始比谁记得更有选择、更稳定、也更「像人」。大模型的长期记忆不再只是论文里的性能指标,而是决定「能不能长期被用、敢不敢被信任」的关键能力。
从 Titans 到 Hope,长期记忆在为智能体「打基础」
今年 8 月中旬,谷歌为 Gemini 推出了两项重大更新,分别是基于聊天上下文的「自动记忆」功能和保护隐私的「临时聊天」模式。
顾名思义,「自动记忆」是指 Gemini 会通过学习用户过去的聊天记录,记忆对话中的关键细节、用户偏好、长期项目背景、反复出现的需求等,并在后续回答中实现主动的个性化回答。
类似的变化并不只发生在 Gemini 身上。过去一年,从 ChatGPT、豆包到 11 月推出的讯飞星火 X1.5,几乎所有头部 AI 助手都在通过引入「长期记忆模块」,努力让大模型在跨会话、跨场景中保持连续性,让 AI 能够更新并记忆用户画像、历史任务状态和关键决策信息。

图片来源:科大讯飞
不过继续向上追溯,这一波产品层的变化,并不是孤立发生的,而是 2025 年大模型底层技术演进的直接结果。
首先被重新确认的一点是,长上下文不是大模型记忆的终点。
超长上下文仍然重要,但它越来越被视为一种「放大的短期记忆」——成本高、也无法判断哪些信息值得被长期保留。而 Titans 的意义,并不在于把窗口再拉长,而在于明确区分:注意力只是短期系统,长期记忆必须是一个可持续更新的组件。
11 月,谷歌更是提出将模型训练过程也视为一层记忆(Nested Learning),并给出了升级版的 Hope 架构,开始把「记忆」理解为多时间尺度的连续体,短期上下文、中期状态、长期经验不再是割裂的模块,而是按更新频率和稳定性分布在同一套学习系统中。
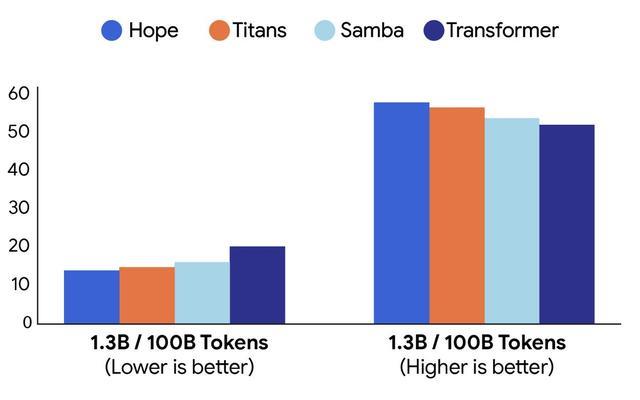
Hope 与 Titans、Transformer 架构对比困惑度(左)和常识推理(右),图片来源:谷歌
与此同时,长期记忆的重心从「记住文本」转向「记住经验」。过去常见的做法是用向量数据库或知识库做 RAG,把它当成模型的「外部硬盘」。但现在这种做法正在被重新审视,长期记忆不只是检索答案,而是需要参与推理过程,影响模型的决策和行为。
还是在 11 月,谷歌提出 Evo-Memory benchmark 和 ReMem 框架,明确将长期记忆放入智能体的工作流中考察:模型是否能在连续任务中提炼经验、复盘策略,并在后续任务中真正用上。长期记忆不再只是为对话服务,而是直接决定智能体是否具备持续进化能力。
事实上,字节跳动与清华联合提出的 MemAgent,则通过强化学习训练模型在超长上下文中「学会取舍」,让模型主动形成长期记忆习惯,而不是被动堆叠文本。这些工作虽然路径不同,但都指明了长期记忆必须逐步内化为模型能力,而不只是工程外挂。
长期记忆的中国路线:MiniMax/豆包/DeepSeek有何不同思路?
今年年初,MiniMax 宣布了首个线性注意力架构大模型开源,官方就指出现有智能体的「长期记忆」大多只是外挂 RAG 工具,这严格意义上不算记忆。
事实的确如此。在早期实践中,向量数据库加 RAG 几乎是默认方案:需要记住什么,就检索什么。但随着智能体逐渐承担多步骤任务,这种「查完就走」的记忆方式开始显得吃力。
最近豆包手机引爆了业界关于AI手机的讨论,其实豆包在 Agent 体系中关于长记忆的探索也具有很强的代表性,其长期记忆被拆分进整个工作流,用来保存用户画像、任务状态、阶段性结论,甚至失败经验。
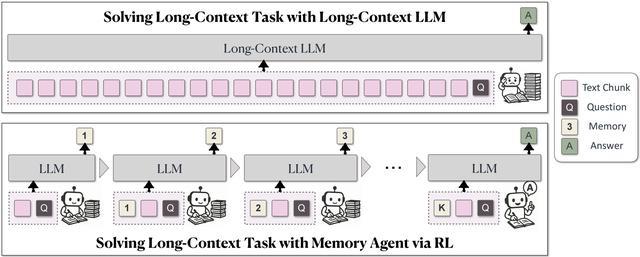
MemAgent 的基本结构,图片来源:字节跳动
MemAgent 这一类方案,本质上并不是在扩展上下文长度,而是在训练模型理解哪些信息会影响下一步决策。简言之,记忆不再是查资料,而是参与判断。
从这个角度看,字节与清华联合提出的 MemAgent 并不是一篇孤立的学术工作。它关注的,并不是如何压缩文本或扩展容量,而是通过强化学习,让模型在超长上下文和连续任务中逐渐学会「取舍」。模型需要理解哪些信息值得保留,哪些只适合短期使用,甚至哪些应该被主动遗忘。
背后也体现了一种非常明确的判断,即长期记忆如果不能改变模型的行动策略,本质上仍然只是工程缓存。
正如前文所提,不论是行业的实践,还是围绕智能体展开的多种系统设计,都在强调对「过程信息」的保留。这也解释了为什么强化学习开始被用于「记忆行为」的训练,而不是简单地扩大知识库。
与之不同的是,MiniMax 在今年初就通过线性注意力等架构创新,把模型可处理的上下文推至百万乃至数百万 token 级别。
这并不是单纯为了刷新指标,而是试图用容量换取系统简化。当模型本身一次可以稳定「看见」更多内容时,部分原本需要频繁调度、反复检索的外部记忆,就可以暂时被收进上下文视野之中。
但 MiniMax 的实践并没有停留在「超长上下文窗口」。

图片来源:MiniMax
相反,他们在此基础上继续引入独立的记忆层,用于管理长期知识与经验。先解决「装不装得下」,再讨论「该不该留下来」。在这种框架下,长期记忆不再完全依赖于频繁的 RAG 调用,而是通过更大的模型内视野与更少的系统切换,降低整体复杂度。
而 DeepSeek 的策略,则构成了一个有意义的对照。DeepSeek 并没有在模型侧押注复杂的长期记忆机制,而是将其明确外置,通过 RAG、向量库或各类记忆组件完成。倒不是在回避问题,而是基于一个更克制的判断:
长期记忆高度依赖具体场景,不同应用需要的记忆形态差异巨大,与其在模型里「一刀切」,不如提供一个高质量的推理核心,让开发者自行组合记忆方案。
写在最后
2025 年,大模型长期记忆真正发生变化的,并不是某一项指标被刷新,而是它的角色定位被彻底改写了。从早期依赖 RAG 的「外接硬盘」,到今天逐步进入模型结构与智能体工作流,长期记忆开始成为影响决策、塑造行为的一部分,而不只是被动存储信息的容器。
或许可以这么说,未来大模型之间真正的差异,不再只体现在模型规模或推理速度上,还在于一套成熟、可控、可持续演化的记忆机制。因为只有当一个模型真正记得住、也管得住,它才有可能被长期使用、反复依赖,甚至被交付更大的决策权。
CES2026开幕在即!(1月6日-1月9日)
作为中国报道科技展会最悠久、最深入、最专业的新媒体,雷科技CES2026报道团正在进行紧张的前期筹备。届时雷科技将派出史上最大规模的CES报道团,并由雷科技创始人兼总编辑罗超带队,对CES2026进行一线、专业和立体报道,敬请期待!

大家都在看
-

贵州茅台退出前十,18只科技股霸榜前20!2026年最该盯的20家公司 A股5000多只股票,你每天翻来翻去,真正值得长期关注的到底有几只?2026年二季度,公募基金前十大重仓股出现“6进6出”的大幅调整。贵州茅台从长期占据的头部位置一路滑落至第30大重仓股。消费与医药龙头近十年来首 ... 科技之最07-29
-

腾讯首进前百、华为守位、美的反超LG电子,中国科技军团世界500强集体跃升 7月28日下午,2026《财富》世界500强排行榜出炉。今年《财富》世界500强排行榜企业的营业收入总和约为43.1万亿美元,超过全球GDP的三分之一,比去年增长了约3.2%。所有上榜公司的净利润总和同比大幅增长约14%,约为3 ... 科技之最07-29
-

身有桎梏 心向鸿鹄——记国防科技大学计算机学院研究员王戟 国防科技大学计算机学院研究员王戟(中)在图书馆与学生讨论(2026年5月20日摄)。范军威摄(新华社发)和王戟第一次见面,约在学校图书馆“高地文库”。一室清寂之中,57岁的他轻推轮椅,面带微笑而来,不见疲态。 ... 科技之最07-29
-

阿基米德:那个浴缸里裸奔的数学家,凭啥让罗马士兵都怕他? 如果你以为数学家都是穿着长袍、一脸严肃的老头子,那你一定没听说过阿基米德。这位古希腊老兄,堪称历史上最“炸”的科学家——不是因为他发明了炸药,而是他的人生实在太有料了。浴缸里的惊天发现事情是这样的:国 ... 科技之最07-27
-
长鑫科技十年DRAM量产,给国产存储留下了怎样的商业范本? 长鑫科技,这家从合肥起步的DRAM(动态随机存取存储器)企业,用了十年时间,从零做到全球第四、中国第一,即将于2026年7月27日登陆科创板。成功上市后,它不仅让合肥国资收获了百倍级账面回报,更让国内其他半导体 ... 科技之最07-27
-
3.3万亿!长鑫科技总市值居A股第一,中一签赚2万,幻方量化又赚麻了 7月27日,中国“存储之王”长鑫科技(688825.SH)正式登陆上交所科创板,开盘报49.5元/股,较8.66元/股的发行价大涨471.59%,市值达3.31万亿元,超越工商银行,居A股总市值第一。以开盘价计算,中一签(500股)投资 ... 科技之最07-27
-

值得珍藏:科技核心“五巨头”,AI赛道,半导体龙头,汽车芯片等 深耕二级市场产业投研整整二十年,常年跟踪国内科技全产业链的发展脉络。如果把国内高端科技产业链看成一座完整的金字塔,有五个细分领域算得上塔尖核心支柱,业内俗称科技五巨头,分别是AI算力芯片、半导体设备、晶 ... 科技之最07-27
-

三星堆600余根象牙“搬新家” 独家揭秘科学守护之路 央视网消息:1986年7月,三星堆遗址祭祀坑被发现,四十年来,古蜀文明的密码不断破译。近日,纪念三星堆遗址祭祀坑发现四十周年暨古象牙研究与保护学术研讨会正在四川广汉召开,其中,三星堆遗址袁家院祭祀区考古研 ... 科技之最07-26
-

长鑫科技科创板挂牌倒计时:国产存储全产业链5大方向核心标的深度拆解 (来源:金融小博士)2026年7月23日晚,长鑫科技发布上市公告书,确认公司股票将于7月27日正式在科创板挂牌,发行价8.66元/股,对应市值约5800亿元(绿鞋前),部分机构给出中性预期市值2万亿—3万亿元。作为中国规 ... 科技之最07-26
-

脑科学重磅结论:孩子大脑最高效休息,睡觉只排第二 多数家长一直存在一个育儿误区:孩子学习犯困、专注力下降、用脑过度时,第一反应就是让孩子睡觉、趴桌午休。但多项脑科学实验、中科院心理研究所对照研究给出颠覆性结论:睡觉并非孩子白天最高效的脑力修复方式,真 ... 科技之最07-26
相关文章
- 长鑫科技科创板挂牌倒计时:国产存储全产业链5大方向核心标的深度拆解
- 脑科学重磅结论:孩子大脑最高效休息,睡觉只排第二
- 阿基米德:千年罕见科学天才,成就领先世界两千年
- 八大无可替代金属之王盘点,硬核科技关键卡脖子材料全梳理
- 象牙塔到产业高地:华工科技二十七年完整发家史
- 颠覆百年格局!35岁王虹登顶世界数学巅峰,重塑中硬核科技话语权
- 德明利这次科技股调整以来,是跌得最凶狠的个股之一!这是机构和主力抱团的杰作,涨得有多疯狂,跌得有多离谱!
- A股:突发扰动,美股科技七巨头大跌!今日周五将迎来风雨?
- 十年后最值钱七类核心科技揭晓 半导体标杆企业一次性讲透彻
- 碾压时代的五大科学巨人,看懂他们,才算读懂人类科技史
- 别掐灭孩子的好奇心!这才是科技强国最该做的基本事
- A股头条:证券交易印花税上半年进账1549亿,增幅创十年之最;多家海外科技巨头加码数据中心业务,OpenAI将云支出预期上调至7500亿美元
- 哈工大航天核心优势,为何总有一群学生总师站在最前沿?
- 中科大vs华中科大,两大顶尖科技名校,到底谁更值得报考?
- 别被账面利润迷惑!国产半导体设备十强真实实力排名曝光
- 拒绝套路!5本顶流科技修仙神作,用科学推演天道,越看越上瘾
- 都有“世界之最”,到底谁最牛?
- 中国科技:哪些世界第一,哪些还在追赶?
- 让牛顿发现引力的不是苹果,而是非凡的数学思维!
- 科技牛为何还在,支撑点在哪
热门阅读
-
 1
万事胜意不能乱说的原因?告诉你万事胜意该对谁说 12-09
1
万事胜意不能乱说的原因?告诉你万事胜意该对谁说 12-09 -
 2
科威特第纳尔为什么那么值钱?比美元值钱的货币盘点 12-22
2
科威特第纳尔为什么那么值钱?比美元值钱的货币盘点 12-22 -
 3
撕心裂肺十大催泪情歌,10首哭到崩溃的歌曲 12-24
3
撕心裂肺十大催泪情歌,10首哭到崩溃的歌曲 12-24 -
 4
不敢公布马航真实原因,内幕曝光简直太惊人! 12-25
4
不敢公布马航真实原因,内幕曝光简直太惊人! 12-25 -
 5
陈百强什么原因怎么走的,陈百强85事件是什么 01-05
5
陈百强什么原因怎么走的,陈百强85事件是什么 01-05 -
 6
麻将公式一定要背下来,麻将手气背转运小妙招 01-19
6
麻将公式一定要背下来,麻将手气背转运小妙招 01-19 -
 7
科学家发现上帝的存在,神仙真实存在的十个证据 04-29
7
科学家发现上帝的存在,神仙真实存在的十个证据 04-29 -
 8
8