怎么一眼看出“这是 AI 译的”?5 个机器翻译的“破绽”清单
做审校的人 ,大概都遇到过这种时刻:一份稿子读起来挺顺,可心里总有个声音在嘀咕—— 这到底是人译的 ,还是机器跑的?
这个判断越来越重要。一方面 ,纯机翻未经审校就交付,可能埋着你看不见的雷;另一方面,客户、出版方、甚至法规,都开始在意“这份译文怎么来的”。但难点也在这里: 现在的 AI 译文太流畅了,流畅到很难一眼分辨。
好在 ,机器翻译再像人,也会在一些地方留下“指纹”。今天就给你一份实操清单—— 5 个最容易识破机翻的破绽 ,从最好抓的,到连老手也容易看走眼的。

图 1 | 5 个“破绽”总览:越往后越隐蔽
01 | 先认清 :机翻的错,分“显错”和“隐错”
在看清单之前 ,得先建立一个关键认知。机器翻译的错误,分两种,危险等级完全不同。
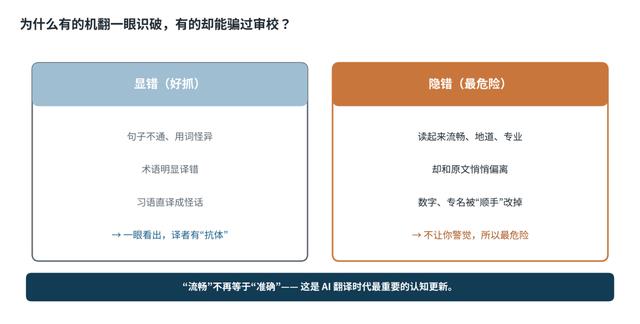
图 2 | “显错”好抓,“隐错”最危险
一种是 “显错” :句子不通、用词怪异、术语明显译错。这类错误一眼能看出来,受过训练的译者对它有“抗体”。 另一种是 “隐错” :译文读起来流畅、地道、专业,却和原文悄悄偏离——数字被顺手改了、专名被换了、一句话的逻辑被微妙地扭转了。它穿着体面的外衣,不让你警觉,所以最危险。
所以这份清单的逻辑是 :前两个破绽帮你抓“显错”,后三个帮你识破“隐错”。 记住一句话 :在 AI 时代,“流畅”不再等于“准确”。
02 | 5 个破绽清单:从好抓到难辨
破绽 1 术语与专名 “飘移”
这是最常见、也相对好抓的破绽。机器缺乏全局记忆 ,容易在同一份文档里 把同一个术语前后译成不同的词 ;或者把行业专有含义,译成日常通用义。 一个真实案例 :财务文档里的 “IO code”(内部订单码,internal order code),被机器译成了“进出代码(in and out code)”——在目标语里彻底失去了意义。 缩写被错误展开、或该译却没译 ,也是同类信号。审校时,盯住术语一致性和专名,往往一抓一个准。
破绽 2 习语与文化梗 “直译翻车”
机器擅长字面 ,不擅长“言外之意”。习语、双关、俗语,最容易被它逐字直译成怪话。 比如法语里表示 “心情低落”的 “avoir le cafard”,字面是“有蟑螂”;机器可能真的译成 “to have the cockroach”,在英语里不知所云。 中文这边同理 ——歇后语、成语、谐音梗被直译后,要么变得荒诞,要么平淡得失了味道。凡是文化意象浓的地方,都值得多看一眼。
破绽 3 “过度流畅”却悄悄偏离原意
从这里开始 ,进入“隐错”区,难度陡增。神经机器翻译的流畅度极高,而 这种流畅 ,恰恰会掩盖语义的偏离 。研究发现 ,机器翻译最常见的错误类型,正是“词/短语误译”和“逻辑不清”,此外还有漏译(把原文某部分悄悄丢掉)和增译(凭空加出原文没有的内容)。 一个反常识的经验法则 :一个本该很难译的句子,机器却给了你出奇通顺的译文——这可能不是它厉害,而是它在“编”。 译文太顺 ,反而要回头多问一句:对吗?
破绽 4 虚词膨胀 + “贴源”痕迹
这是个很技术、却很灵的信号。研究观察到 ,机器翻译倾向于 过度使用虚词 ——冠词、介词、连词等,某些场景下虚词用量最多可比人工高出约 23%。如果一段译文读起来“的、了、在、和”异常密集、显得啰嗦,这可能是个线索。 另一个 “贴源”痕迹是:译文过度贴近原文 ——语序被原样保留、每个词都被机械地译出(哪怕它在目标语里毫无意义)。这种挥之不去的“翻译腔”,正是机器“照着原文搬”的副产品。
破绽 5 快得反常、整齐得可疑
最后一个破绽 ,不在文字里,在“节奏”里。人工翻译有它的物理极限:一个译者认真工作,每天通常也就 2000–3000 词 。如果一份海量稿件几分钟、几小时就交付了 ,这本身就是一个值得警惕的信号。 还有一招很实用 :把译文读出声。 机器译文的语气和正式度常常是 “均匀”的,缺少人类那种随上下文自然起伏的调整;读出声时,如果某处语气或文体突然跳变,那里很可能就是机器的接缝。
03 | 一个重要提醒 :别迷信“AI 检测器”
看到这里 ,你可能会问:那我直接用“AI 检测工具”一键判断不就好了?
恐怕不行。一项发表于教育诚信领域期刊的研究评测了 14 款 AI 检测工具,发现 它们的准确率常常低于 80%,有的表现甚至不如抛硬币 ;而且这些工具普遍有一种偏见——容易把 AI 文本误判成人写的。更要命的是,针对“从非英语机翻成英语”的文本,检测准确率还会再下降约 20%。
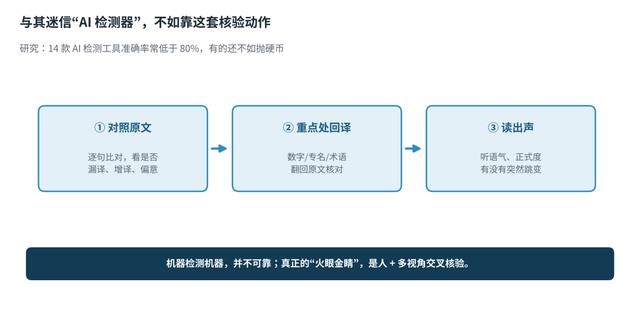
图 3 | 与其迷信检测器,不如靠这套核验动作
换句话说 , 用机器去检测机器 ,本身就不可靠。 真正靠谱的 ,还是回到人的判断,加上几个朴素却有效的动作:
① 对照原文 逐句比对 ,看有没有漏译、增译、偏意; ② 重点处回译 ——把数字、人名、专名、术语翻回原文核对,这些是“隐错”重灾区; ③ 读出声 ,听语气和正式度有没有突然跳变。这三步,比任何检测器都管用。
结语 | 会 “抓机翻”,是 AI 时代审校的基本功
这份清单的意义 ,不是教你去“揪出用了 AI 的人”——AI 辅助本身完全正当。它真正的价值在于:帮你练就一双 分辨 “流畅”与“可信”的眼睛 。
因为在机器译文越来越像人的今天 ,译者和审校最稀缺的能力,已经不是“产出流畅的译文”,而是 成为译文与原文之间那个可靠的 “真值锚点” ——判断这一句到底有没有偏、有没有“编”、有没有被流畅蒙混过去。这,才是机器拿不走的本事。
互动话题 : 你抓到过哪些印象深刻的 “机翻破绽”?有没有那种“读起来特别顺、其实是 AI 编的”翻车案例?欢迎在评论区分享你的“火眼金睛”~
也正是因为 “流畅不再等于可信”, Lingualite 把“多视角交叉核验”做成了产品能力 ——多个智能体基于不同视角并行翻译同一段原文,差异点被自动标注出来,那些最可能藏着“隐错”的地方,会被清清楚楚地摆到译者面前。
机器负责把可疑处 “晒”出来,人负责做最终裁决。与其靠一双眼睛硬扛,不如让流程帮你把破绽显形——这,正是 AI 时代审校该有的底气。
关于 “如何让流畅不再等于可信”的更多思考,欢迎关注本公众号,与我们一起持续探讨。
· 机器翻译常见错误类型(词/短语误译、漏译、增译、逻辑不清等)及术语一致性问题:多份语言行业质量评估资料与机器翻译错误检测研究。
· 机器翻译“虚词膨胀”“过度贴源”等文体特征,以及通过对照原文、回译进行核验的方法:AI 译文检测与质量保证实践指南(2026)。
· AI 检测工具可靠性研究:对 14 款检测工具的评测显示其准确率常低于 80%,并对非英语机翻文本识别能力显著下降(International Journal for Educational Integrity 相关研究)。
大家都在看
-
曾火爆全网的老牌武侠大变样!卸下包袱之后,如今反倒更受欢迎 成年人的世界,时间是最奢侈的消耗品。白天被会议和邮件填满,晚上还要应付生活琐碎。好不容易挤出一小时想放松,打开游戏却发现,迎面而来的是密密麻麻的任务清单、限时活动,还有永远追不上的进度条。那一刻,连打 ... 机械之最06-23
-

竹筒藏香 时光酿“酸”(我与非遗) 杨春兰在采茶。蒸青摊凉揉茶竹筒装茶埋茶发酵捣碎压饼晾晒成品块状酸茶杨春兰到德宏州图书馆开展酸茶制作研学授课。 受访者供图杨春兰在泡酸茶。 本版照片除标注外均为曹 策摄杨腊三(中)向村民们传授采茶技巧。 受访 ... 机械之最06-23
-

信用卡加快“瘦身”提质(大数据观察) 数据来源:中国人民银行 制图:张芳曼相关部门公布的2026年第一季度支付体系运行总体情况显示,截至一季度末,全国共有信用卡和借贷合一卡6.87亿张。这一数量较2022年第三季度8.07亿张的峰值减少约1.2亿张。有不少观 ... 机械之最06-23
-
Anthropic走出危机?这200家公司独享Mythos特权 美国政府出口管制令刚落,坊间以为Anthropic最强模型Mythos要彻底消失。结果彭博社一锤炸响:仍有200多家银行和科技巨头,通过「玻璃之翼计划」继续使用Mythos预览版挖网络漏洞!美国还有人能使用Claude Mythos!据 ... 机械之最06-22
-

守护三江源的人 作者:新华每日电讯记者王金金 海报设计:陈琰泽 30多年来,从孩童到壮年,牧民各求从未离开过黄河源的草场。他日复一日用尺量草,一度为脚下的牧草疏薄而忧心,又喜看近10年来牧草重新挺拔。 朝朝暮暮守护,像各求 ... 机械之最06-22
-
AI写歌月入十几万?我实测了下,发现AI歌曲最大价值是营销 文章开始之前,给大家听一下我们用AI做的一首《雷科技之歌》。初代《中国最强音》总冠军曾一鸣在用真人演唱迎战AI作品《泪海》后,曾公开给出一个判断:“再过一段日子,各大平台的排行榜,都会被AI音乐屠榜。”这个 ... 机械之最06-22
-

中国智造一线的“师徒”新传:老师傅带出“机器高徒” 成卫东的父亲今年76岁,是天津港老一辈手拉肩扛的工人;到了成卫东工作时,吊车、叉车、拖车等大型机械设备涌入港口,工人们从力气活儿中解放,成为机械操作员;一晃几十年,天津港已经进入“无人化”时代,而成卫东 ... 机械之最06-22
-

爱迪生临死前最想干的事,是想发明一台和死人通话的机器! 这是一个亲手把人类声音和光明锁进机器里的理科神明,临死前最想干的事。没错,这个疯子就是爱迪生。但请别再把他当成课本里那个举着发光小灯泡的慈祥老爷爷了。在真实的历史里,他甚至都没发明出第一个电灯。相反, ... 机械之最06-22
-

高端机械制造升级,为什么表面强化工程的地位越来越重要? 在高端机械制造领域,零件服役条件日益苛刻,对可靠性、耐用性和使用寿命的要求不断提高。在此背景下,表面强化工程正从一道普通工序,发展为高端制造中的关键环节。其原因主要体现在以下几个方面。一、多数机械零件 ... 机械之最06-22
-

1949年,四野14兵团配置强大,却被撤销,主将命运,关乎部队命运 先把话说透:14兵团不是“打残了被迫缩编”,更不是什么高层内斗背锅,它是被主动拆骨的——拆法很硬也很现实,把兵团部的脑子、骨架、规矩全套抽走,拿去给一个新军种当“胚胎”,剩下几支能打的军再分别塞回其他兵 ... 机械之最06-19
相关文章
- 听他们讲述代代相传的实干与担当(党旗在基层一线高高飘扬·跨代共谈 薪火相传)
- 竹筒藏香 时光酿“酸”(我与非遗)
- 信用卡加快“瘦身”提质(大数据观察)
- 薪火相传!听三名党员讲述实干与担当
- Anthropic走出危机?这200家公司独享Mythos特权
- 守护三江源的人
- AI写歌月入十几万?我实测了下,发现AI歌曲最大价值是营销
- 中国智造一线的“师徒”新传:老师傅带出“机器高徒”
- 爱迪生临死前最想干的事,是想发明一台和死人通话的机器!
- 高端机械制造升级,为什么表面强化工程的地位越来越重要?
- 1949年,四野14兵团配置强大,却被撤销,主将命运,关乎部队命运
- 2026年金属非金属矿山排水考试题库:新版试题+解析+技巧,模拟考
- 数字织锦 体育生花——我国数智体育发展观察
- “冷热不均”持续,欧盟经济内生增长动力不足
- 欧洲“职业球员加工厂”首次签约中国球员,足球小将踏上巴萨青训之路
- 用好“义乌发展经验” 关键是因地制宜(每周经济评论)
- 用好“义乌发展经验”  关键是因地制宜(每周经济评论)
- 小酥肉“踩线” 手擀面“变味” ESG才是食品行业真正“防腐剂”
- 机械工程、机械电子、机器人工程,三大机械专业咋选?一条讲透!
- 机械专业进什么厂更吃香?半导体是首选
热门阅读
-
 1
天下第一暗器暴雨梨花针,传说中的唐门暗器做出来了 07-13
1
天下第一暗器暴雨梨花针,传说中的唐门暗器做出来了 07-13 -
 2
汽车投诉排行榜前十名汽车 问题最多的就是这些车 07-13
2
汽车投诉排行榜前十名汽车 问题最多的就是这些车 07-13 -
 3
世界上最牛挖掘机,甚至可以挖穿一座城市 11-05
3
世界上最牛挖掘机,甚至可以挖穿一座城市 11-05 -
 4
世界最大核潜艇制造厂,产量远超中美法 11-20
4
世界最大核潜艇制造厂,产量远超中美法 11-20 -
 5
5
-
 6
6
-
 7
7
-
 8
我国在职正部级领导中,最年轻的是这5人! 08-30
8
我国在职正部级领导中,最年轻的是这5人! 08-30