GPU时代终结?世界最大芯片加持推理狂飙20倍英伟达H100也被干趴
编辑:桃子 好困
【新智元导读】LLM若以每秒1000+token高速推理,当前最先进的GPU根本无法实现!Cerebras Inference一出世,推理速度赶超英伟达GPU,背靠自研的世界最大芯片加持。而且,还将推理价格打了下来。
LLM若想高速推理,现如今,连GPU都无法满足了?
曾造出世界最大芯片公司Cerebras,刚刚发布了全球最快的AI推理架构——Cerebras Inference。
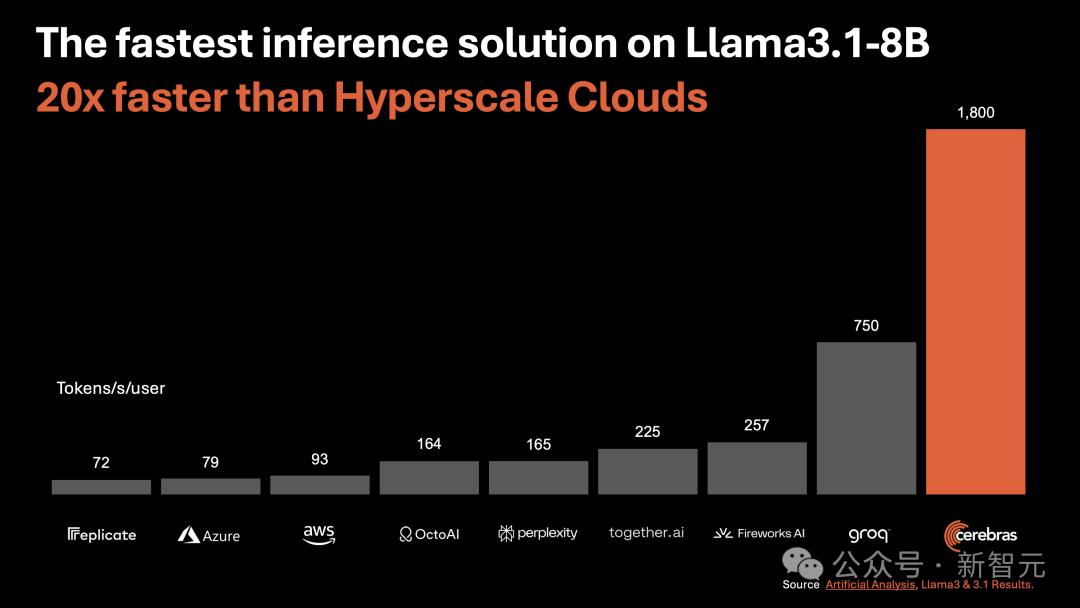
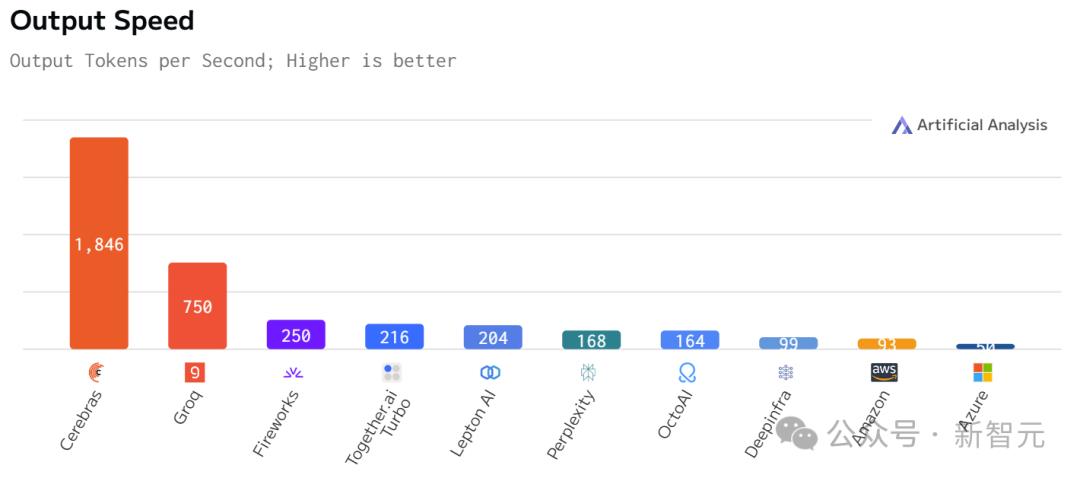
运行Llama3.1 8B时,它能以1800 token/s的速率吐出文字。
不论是总结文档,还是代码生成等任务,响应几乎一闪而过,快到让你不敢相信自己的眼睛。

如下图右所示,以往,微调版Llama3.1 8B推理速度为90 token/s,清晰可见每行文字。
而现在,直接从90 token/s跃升到1800 token/s,相当于从拨号上网迈入了带宽时代。
左边Cerebras Inference下模型的推理速度,只能用「瞬间」、「疯狂」两字形容。
这是什么概念?
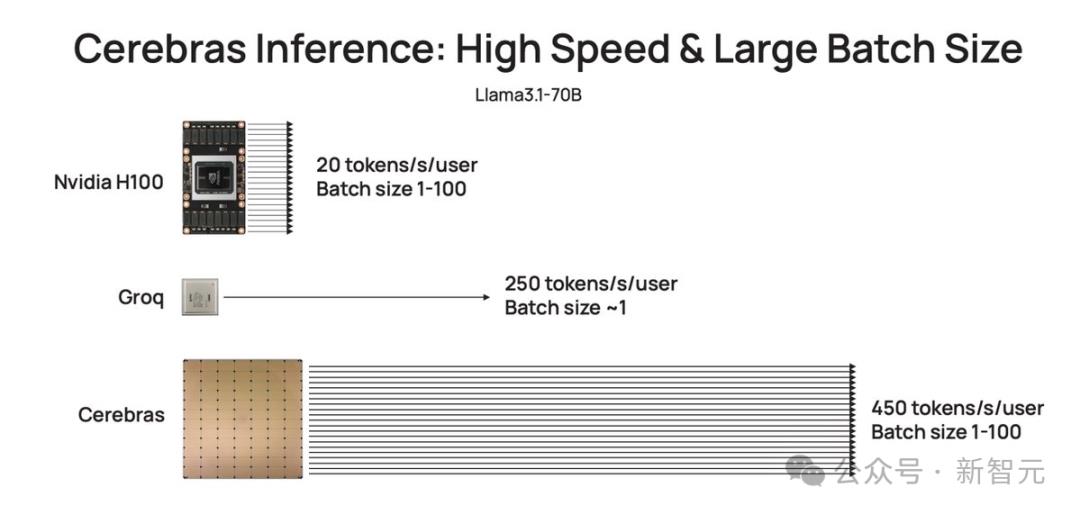
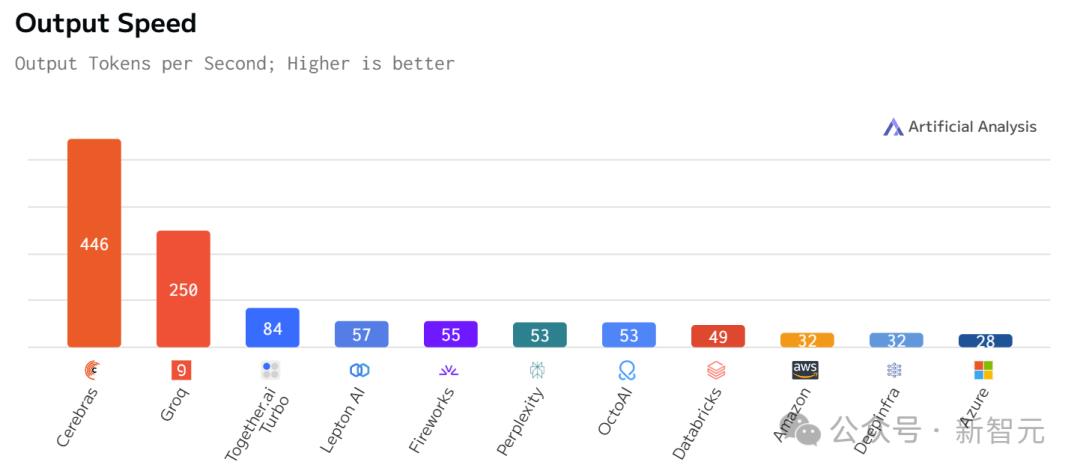
比起英伟达GPU,Cerebras Inference的推理速度快20倍,还要比专用Groq芯片还要快2.4倍。
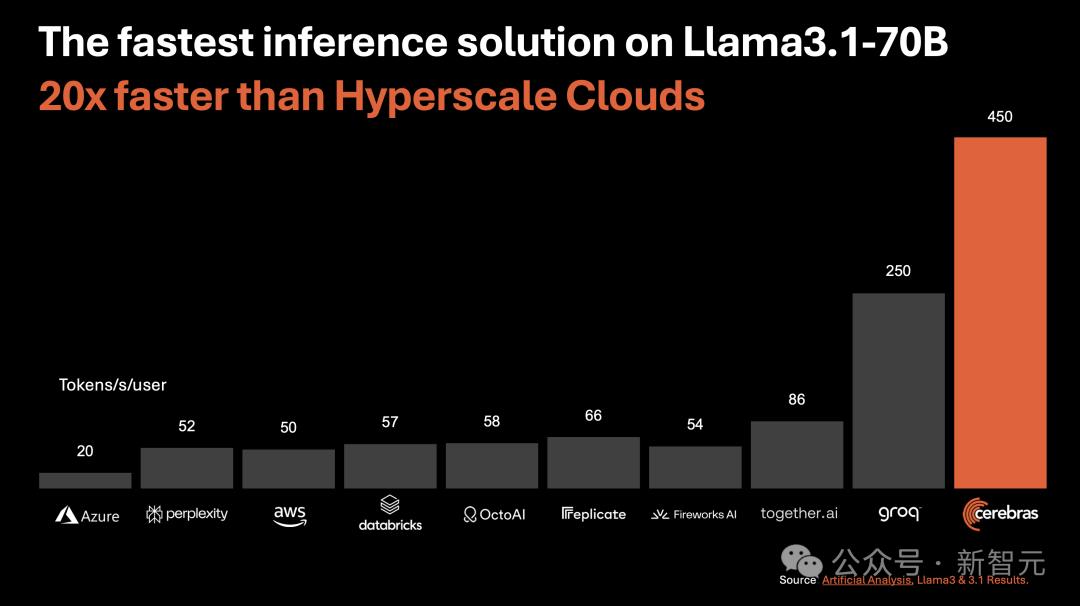
另外,对于70B参数的Llama3.1,可达到450 token/s及时响应。
值得一提的是,Cerebras并没有因为提高LLM的速度,而损失其精度。
测试中,使用的Llama3.1模型皆是采用了Meta原始16位权重,以便确保响应高精度。
最关键的是,价格还实惠。
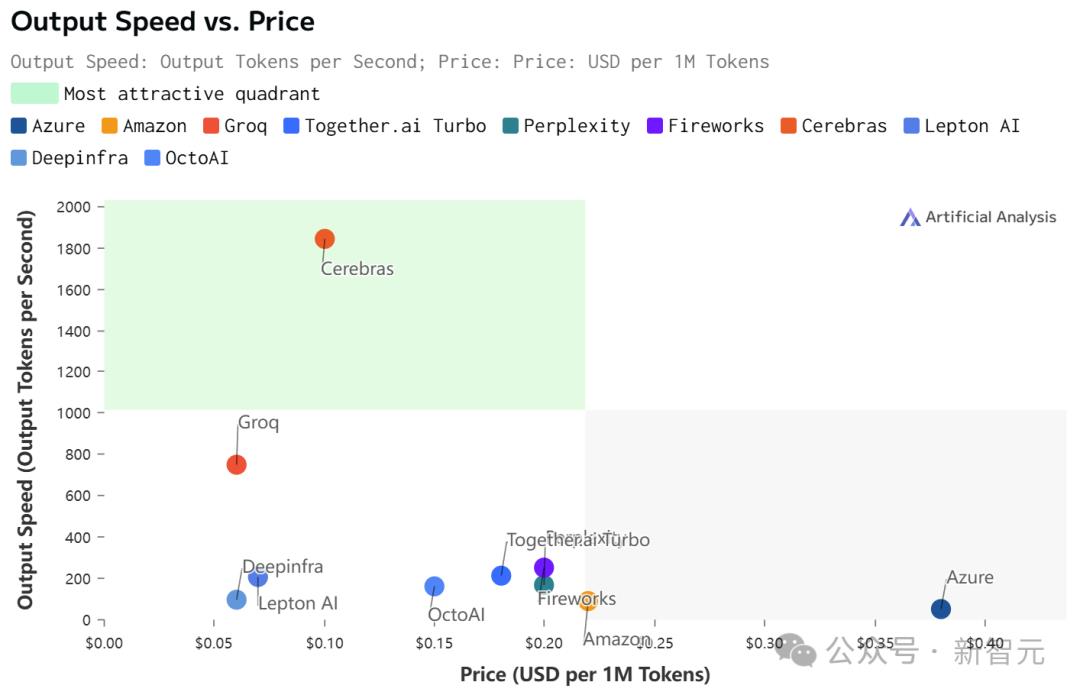
根据官方API定价,Llama 3.1 8B每百万token仅需10美分,Llama 3 70B每百万token仅需60美分。
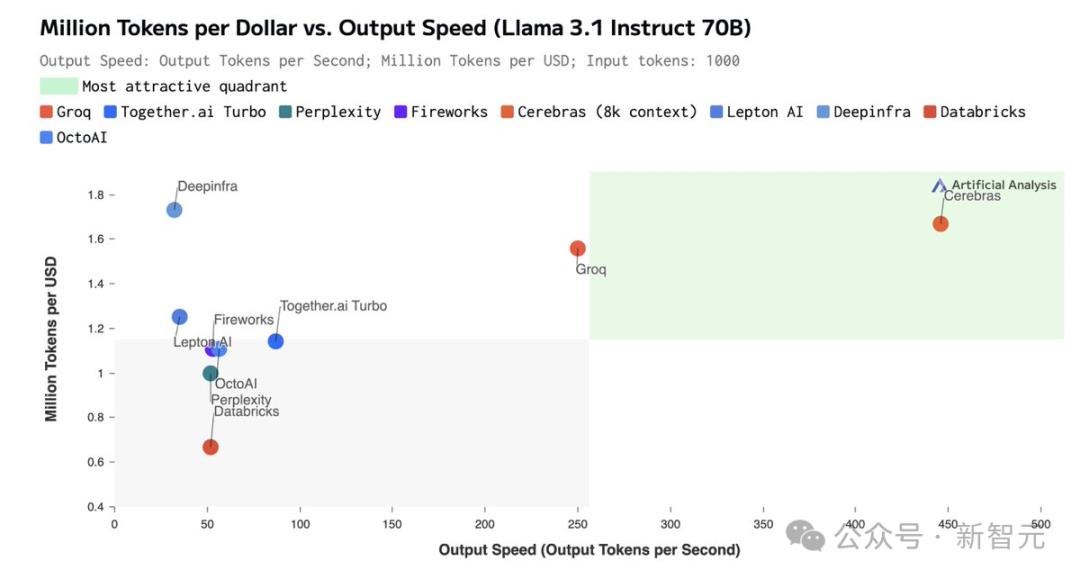
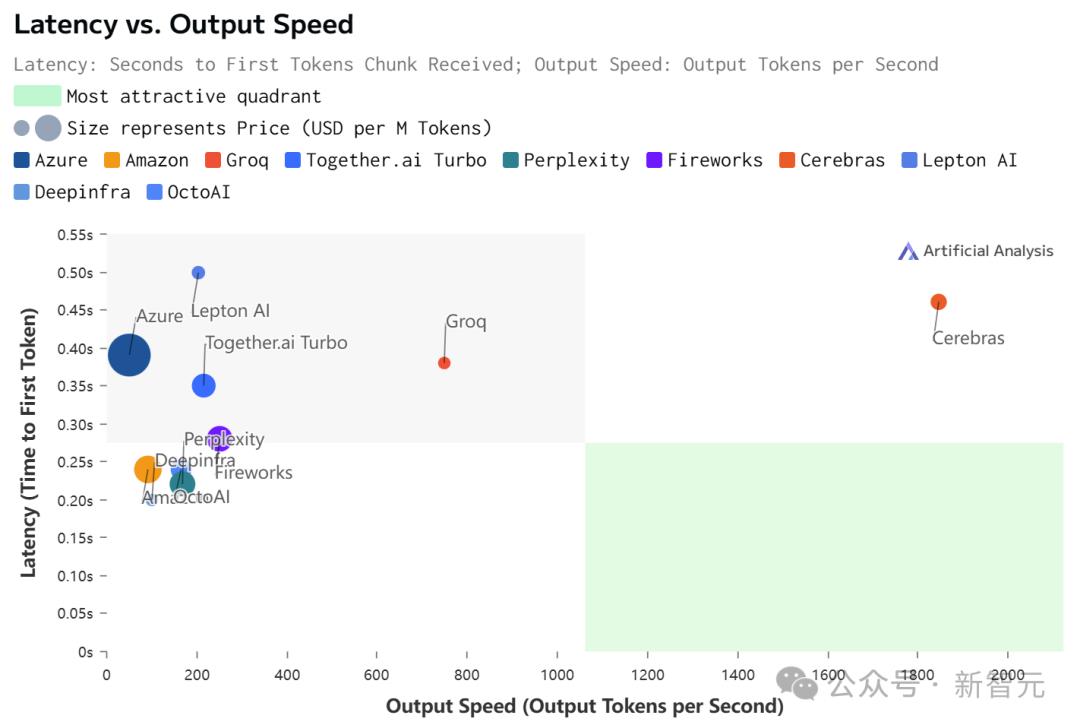
如此之高的性价比,更是打破了业界纪录——
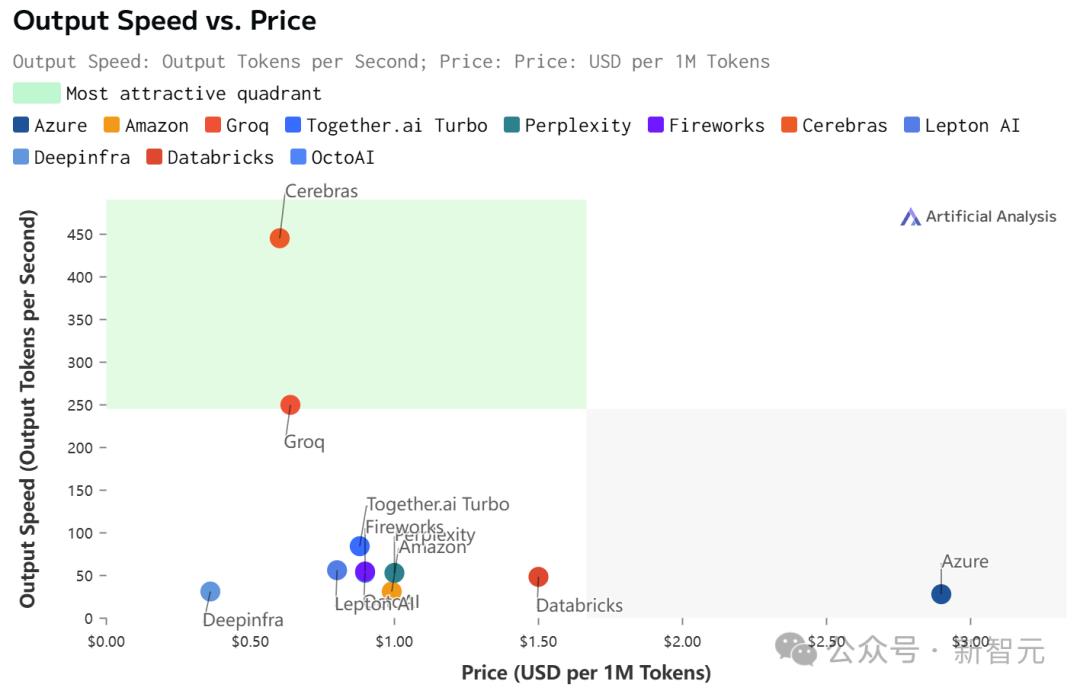
不仅远超之前的保持者Groq,而且和其他平台相比,甚至是隔「坐标轴」相望了。
Artificial Analysis
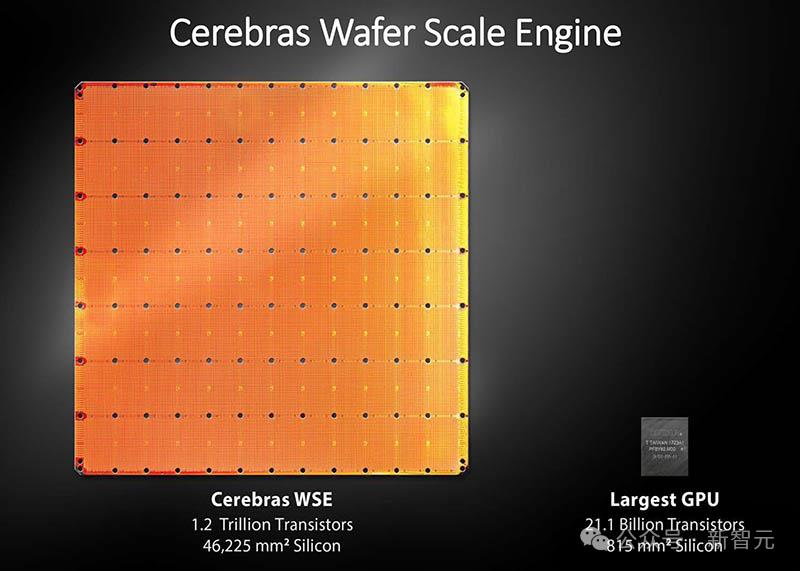
正是因为Cerebras Inference背后,是由自研的第三代芯片Wafer Scale Engine助力,才得以1/5价格快速推理Llama3.1。
看到自家模型推理如此神速,LeCun、Pytorch之父纷纷动手转发起来。


还有网友看后表示,我想要!

推理很慢,英伟达GPU也不中用?
为什么LLM的响应,就像拨号上网加载网页一样,一个字一个字慢慢地吐出?
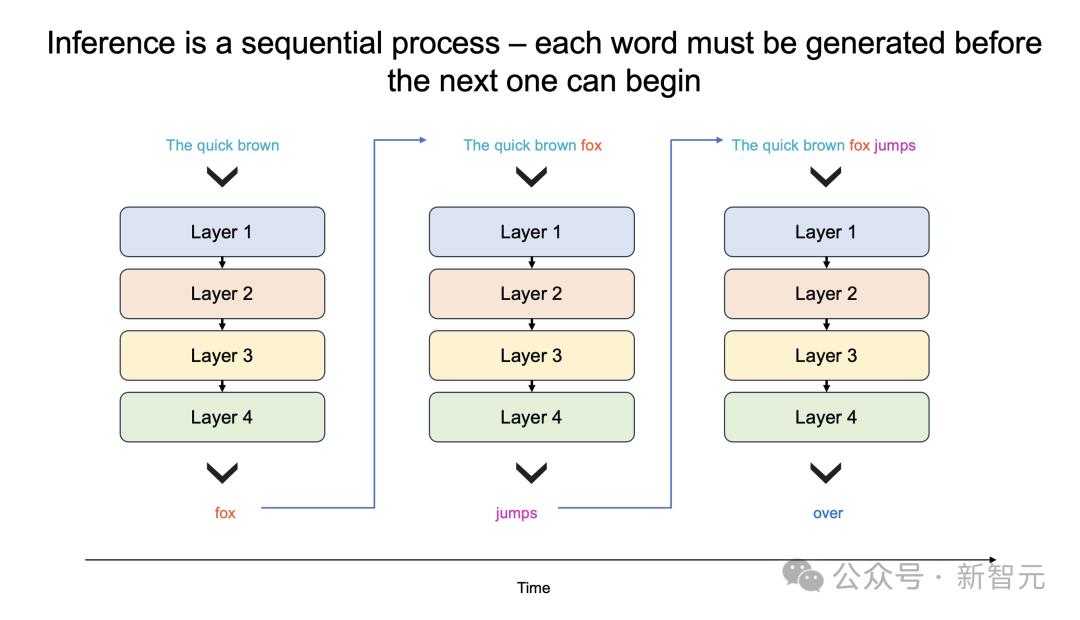
关键原因所在,大模型自身的顺序特性,以及需要大量的GPU内存和带宽。
由于GPU的内存带宽限制,如今推理速度为每秒几十个token,而不是数千个。
更进一步说,大模型每个生成的单词,都必须通过整个模型进行处理,即所有参数必须从内存投入到计算中。

而每生成一个单词,就需要一次处理,以此循环往复。
也就是,生成100个单词需要100次处理,因为「下一词」的预测,皆需要依赖前一个单词,而且这个过程无法并行。
那么,想要每秒生成100个单词,就需要所有模型参数,每秒投入计算100次。
由此,这对GPU内存带宽提出了高要求。
以社区流行的Llama3.1-70B模型为例。
模型有700亿参数,每个参数是16位,需要2字节的存储,那整个模型便需要140GB的内存。
想要模型输出一个token,那700亿参数必须从内存,移动到计算核心,以执行前向推理计算。
由于GPU只有约200MB的片上内存,模型无法存储在芯片。
因此,每次生成的token输出时,需将整个占用140GB内存的模型,完整传输到计算中。
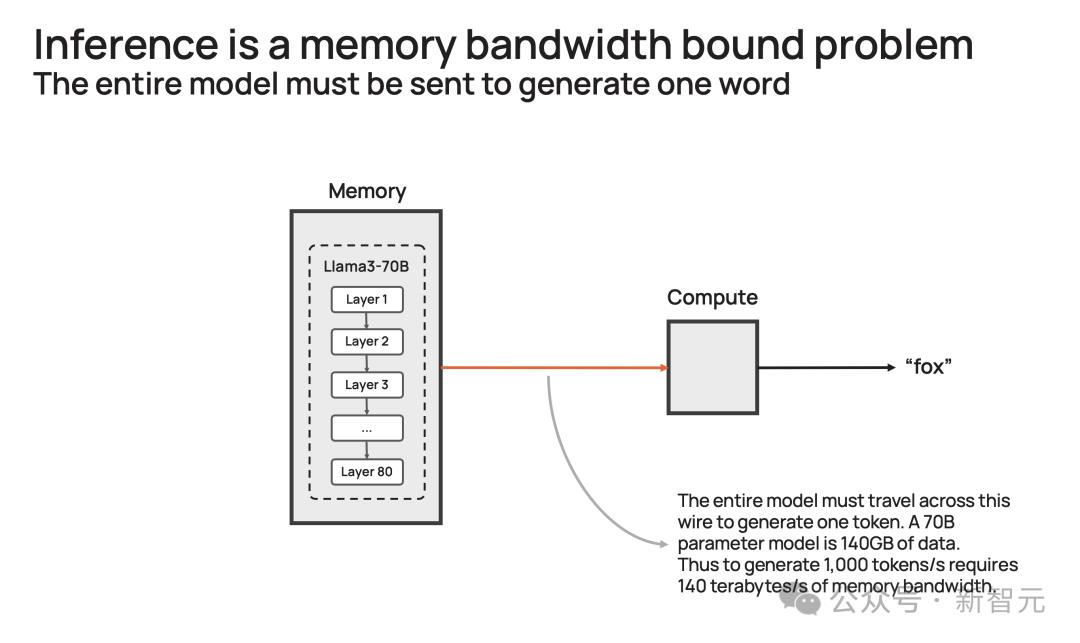
再细算下来,为了实现10 token/s,则需要10*140=1.4 TB/s的内存带宽。
那么,一个H100有3.3 TB/s的内存带宽,足以支持这种缓慢的推理。
而若要实现即时推理,需要达到1000 token/s或140 TB/s,这远远超过任何GPU服务器/系统内存带宽。
或许,你想到了一种「暴力」解决方案,将多个GPU串联搭建DGX系统。
这完全是大错特错,更多的处理器只会增加系统的吞吐量(给出更长响应),并不会加速单个查询的响应时间。
自研世界最大芯片,打破推理想象
那么,Cerebras如何打破这一困局呢?
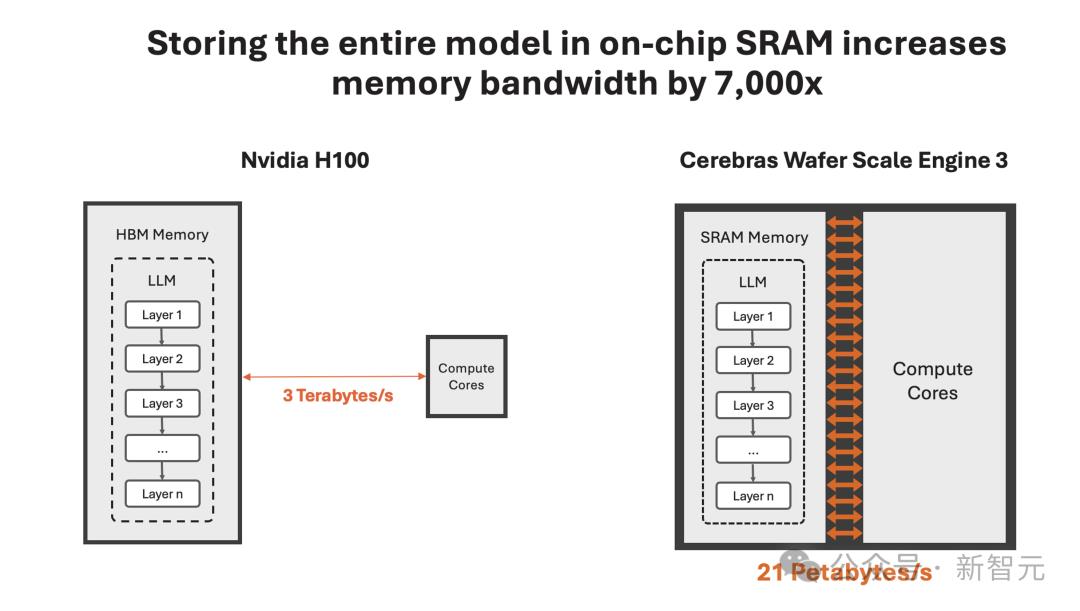
一直以来,这家公司就致力于打造世界上最大芯片,希望将整个模型存储在一个晶片上,以此来解决内存带宽瓶颈。
凭借独特的晶圆设计,WSE-3单个芯片上便集成了44GB SRAM,具备21 PB/s的内存带宽。
单个芯片拥有如此大内存,便消除了对外部内存的需求,以及将外部内存连接到计算的慢速通道。

总的来说,WSE-3的总内存带宽为21PB/s,是H100的7000倍。
它是唯一一款同时具有PB级计算和PB级内存带宽的AI芯片,使其成为高速推理的近乎理想设计。
Cerebras推理不仅速度超快,而且吞吐量巨大。
与小型AI芯片相比,芯片上内存多了约200倍,支持从1-100的批大小,使其在大规模部署时,具有极高的成本效益。
正是有了如此强大的芯片,Cerebras Inference的快速推理得以实现。
它的出现,是为了实现数十亿到万亿参数模型的推理。
如果模型参数超过单个晶圆的内存容量时,研究人员将在「层边界」将其拆分,并映射到多个CS-3系统上。
20B模型适合单个CS-3,而70B模型则至少需要4个这样的系统。
官方表示,未来几周,将会测试更大参数版本的模型,比如Llama3-405B、Mistral Large。
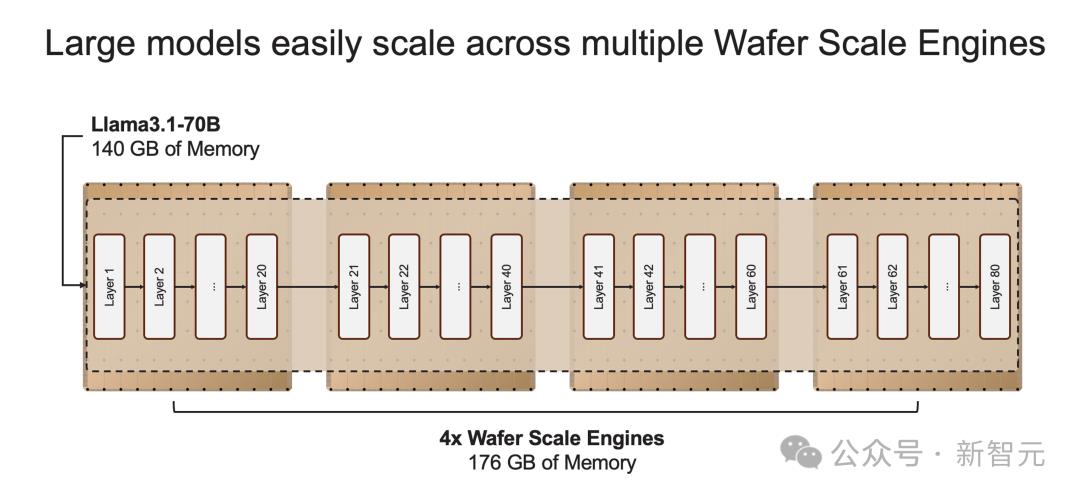
16位精度,不做取舍
推理速率高,并非在模型权重上,做了取舍。
业界中,一些公司试图将模型权重精度,从16位减少到8位,来克服内存带宽的瓶颈。
这样方法,通常会造成模型精度损失,也就是响应结果的准确性、可靠性不如以前。
Cerebras Inference之所以强就强在了,速率和原始权重,皆要顾及。

正如开篇所述,他们采用了原始16位权重运行了Llama3.1 8B和70B。
通过评估,16位模型准确率比8位模型,高出多达5%。尤其是在,多轮对话、数学和推理任务中表现更好。
最优性价比,百万token免费送
目前,Cerebras Inference可通过聊天平台,以及API访问,任何一个人可随时体验。

体验传送门:https://cerebras.ai/blog/introducing-cerebras-inference-ai-at-instant-speed
基于熟悉的OpenAI Chat Completions格式,开发者只需更换API密钥即可集成强大的推理功能。

Cerebras Inference API提供最佳的性能、速度、精度和成本组合。
它是唯一能即时运行Llama3.1-70B的方案,可实现450 token/s,同样使用的是原始16位模型权重。
在此,Cerebras送上大福利,每天为开发者们提供100万个免费token。对于大规模部署,其定价只是H100云的一小部分。

首次推出时,Cerebras提供了Llama3.1 8B和70B模型,而且有能力每天为开发者和企业,提供数千亿token。
接下来几周,他们将增加对更大模型的支持,如Llama3 405B、Mistral Large 2。

有开发者问道,你们提供的rpm(每分钟请求次数)和tpm(每分钟处理token数)是多少?
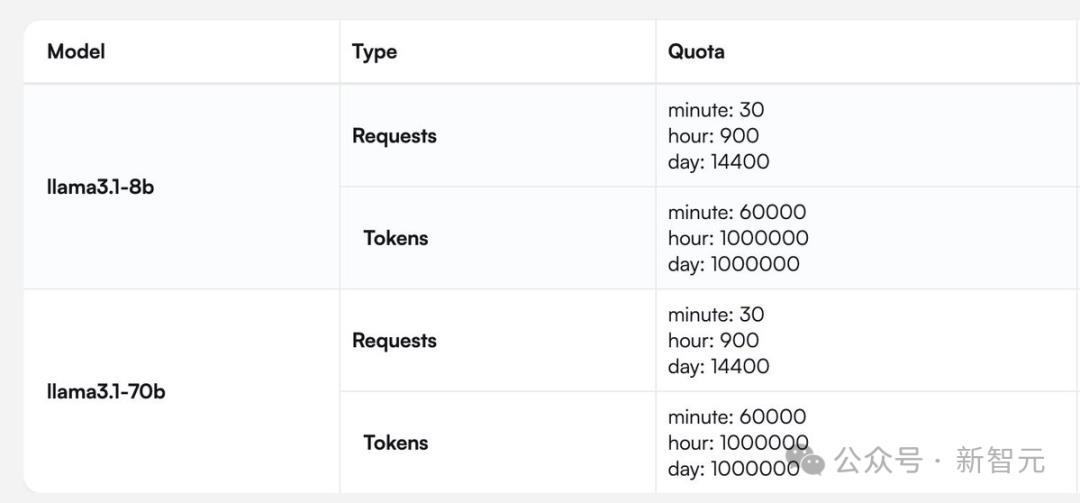
Cerebras提供了一张针对Llama 3.1 8B和70B模型完整的请求/token处理数的图。
快速推理,不只为速度
最后,让我们来聊聊,为什么快速推理非常重要?
通常,LLM会即刻输出自己的全部想法,而不考虑最佳答案。而诸如scaffolding(脚手架)这类的新技术,则如同一个深思熟虑的智能体,会在作出决定前探索不同的可能解决方案。
这种「先思考后发言」的方式在代码生成等严苛任务中,可以带来超过10倍的性能提升,从根本上提升了AI模型的智能,且无需额外训练。
但这些技术在运行时,需要多达100倍的token。
因此可见,如果我们能大幅缩短处理时间,那么就可以实现更为复杂的AI工作流程,进而实时增强LLM的智能。
速度爆表,但上下文只有8K
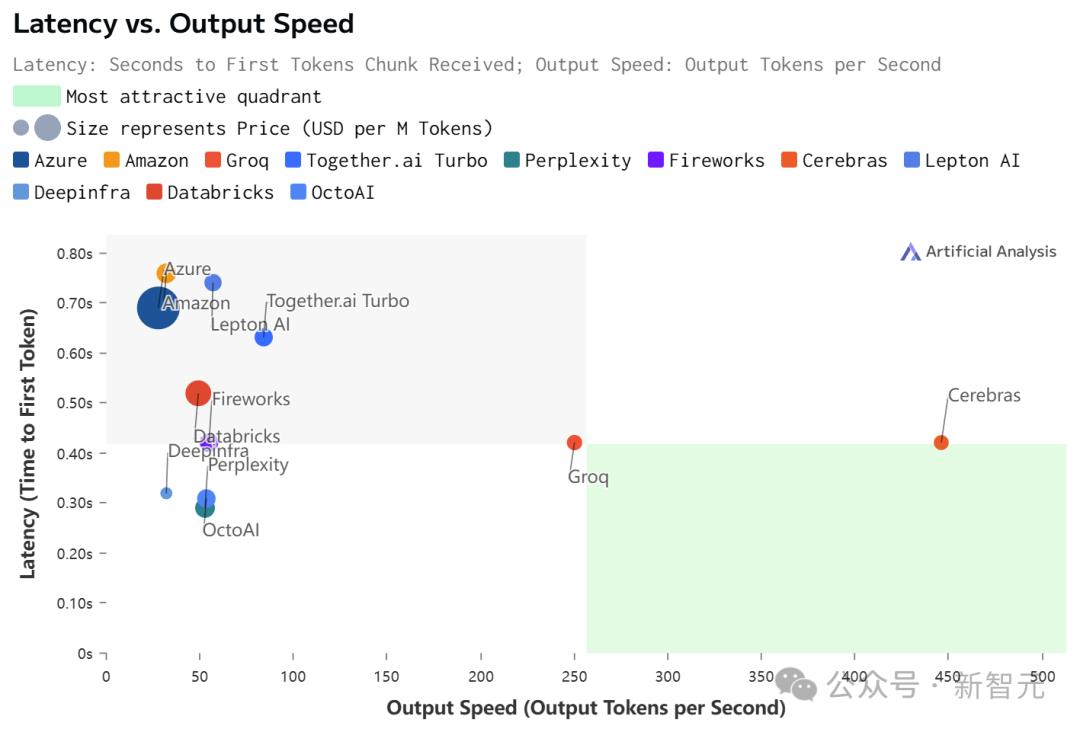
虽然在价格和延迟上,Cerebras都不是最低的。
但极致的速度,确实为Cerebras带来了极致的速度-价格和速度-延迟比。
不过,值得注意的是,在Cerebras上跑的Llama 3.1,上下文只有8k……
相比之下,其他平台都是128K。
具体数据如下:
Llama 3.1 70B
Llama 3.1 8B
参考资料:
https://cerebras.ai/blog/introducing-cerebras-inference-ai-at-instant-speed
https://x.com/CerebrasSystems/status/1828464491677524311
https://artificialanalysis.ai/models/llama-3-1-instruct-70b/providers
大家都在看
-

探秘世界最大宫殿:不止一个“世界之最” “世界上最大的宫殿是哪座?”——这个问题,答案远比你想象的复杂。如果按宫殿建筑群规模算,北京故宫当之无愧;如果按宫殿主体建筑建筑面积对比,法国凡尔赛宫常被视作单体宫殿规模标杆;若论仍在使用的最大皇家住 ... 世界最大07-26
-

世界最大珊瑚礁——大堡礁的微生物与病毒组 大堡礁(Great Barrier Reef)是地球上最大的由生物建造的单一结构。它位于澳大利亚东北海岸,纵贯昆士兰州沿岸,南北绵延约2300公里,总面积约34.4万平方公里。这个庞大的生态系统生活着约400种珊瑚,超过1500种鱼 ... 世界最大07-26
-

全球最大客机A380,突然备降杭州,373名乘客被困机舱超10小时,故障仍未排除!“救护车来了两趟”,乘客:空调也坏了,有人在机舱里晕倒 7月22日晚,阿联酋航空EK302航班(迪拜至上海浦东)因浦东机场天气原因,于21时04分备降杭州萧山国际机场。停在杭州萧山机场货机坪的阿联酋航空A380 图片来源:潮新闻 谢春晖/摄这架A380客机难得现身杭州,不少飞友 ... 世界最大07-26
-

全球最大客机杭州困客通宵!阿联酋航空发致歉信解释,但疑点太多 那一晚,杭州萧山机场的货机坪上,全球最大的客机A380灯光还亮着,仓门紧闭。外面是飞友们举着长枪短炮,兴奋地蹲守“空中巨无霸”;里面是373个困在机舱里的乘客,熬着一夜闷热、焦躁和不确定。这画面反差有点扎心 ... 世界最大07-25
-

一座世界最大火电厂,正在变成综合能源基地 黄河在托克托拐出一道弯,也把一座能源重镇圈在了河套之间。这里有风机迎风转动,有光伏板铺向戈壁,也有冷却塔吐出白汽。煤电、风电、光伏,过去像是三条不同的路,如今在同一片土地上接了起来。这片区域的核心,正 ... 世界最大07-25
-

俄拥有世界最大核武库,但退役中国上校说它没起到任何作用 很多人到现在还没想明白一件事。俄罗斯手里攥着据公开资料约4309枚核弹头,规模居全球前列,可乌克兰的无人机照炸莫斯科,远程打击端掉炼油厂,黑海舰队被无人艇撵出克里米亚。核按钮就在普京办公桌抽屉里,四年都没 ... 世界最大07-25
-

莽山烙铁头最大能长多大?和眼镜王蛇谁才是世界上体型最大的毒蛇 争议极大的莽山烙铁头!曾炒到百万一条,它和眼镜王蛇谁是最大毒蛇?之前的文章,说了一下国内最大的五种蛇,其中提到眼镜王蛇是我国最大的毒蛇,而眼镜蛇只要能排到第四名。因此,有网友提出,这个扣掉了莽山铁头, ... 世界最大07-25
-

六家餐饮企业集体碰壁!全球最大饺子店,离上市还有多远? 拿到了证监会国际司的上市备案,招股书却失效了。这是袁记食品IPO进程中戏剧性的一幕。截至目前,袁记食品拥有4266家门店、年营收超25亿元,按门店数量计已是全球最大的中式快餐品牌。但翻开招股书会发现不止那么简 ... 世界最大07-25
-

前所未有的人工智能失控事故!全球最大的 AI “超市”遭贼了! 7 月中旬,全球最大的AI“超市”遭贼了!事情是这样的,抱抱脸(Hugging Face)是全球最大的AI模型分享和下载站,全球开发者可以把自己训练好的“AI大脑”上传,谁需要就下载。而7月中旬,他们为用户提供服务的生产 ... 世界最大07-25
-

IEA:预计今年可再生能源将超过煤炭,成为全球最大的电力来源 【环球网财经综合报道】根据国际能源署(IEA)最新发布的《电力年中更新》预测,2026年全球电力需求将增长3.6%,2027年将进一步增长3.8%,高于2025年的3%。全球用电量预计将在2027年达到30,700太瓦时(TWh),而2025 ... 世界最大07-25
相关文章
- 前所未有的人工智能失控事故!全球最大的 AI “超市”遭贼了!
- IEA:预计今年可再生能源将超过煤炭,成为全球最大的电力来源
- 2亿欧元身价到底值多少钱?足球世界最大的财富泡沫,还是最精密的商业估值?
- 世界最大客机在杭州困客一夜,阿联酋航空道歉信为何疑点更多?
- 邓煜王虹同摘世界顶级数学奖,是什么让顶尖科学家认定“现在是我们基础科研最好的时代”?
- 中建三局塑强海外高质量发展
- 世界最大蜈蚣!自然界的奇迹!🐅💨
- 日赚六千万的全球最大医院,是救命的殿堂还是生意的江湖?
- 全球最大肉出口国巴西紧急对接欧盟,规避18亿美元肉类出口受阻风险
- 引力一号远海首秀一箭九星 全球最大固体火箭验证机动发射
- 世界上最大的转经筒,就在云南香格里拉的独克宗古城
- 全球最大的黄金ETF SPDR Gold Trust持仓较前日增加2.00吨
- 世界上最大的兔子,站起来比小孩还高,性格却胆小如鼠
- 罗德里戈给库库留言:恭喜夺冠,我们在世界最大俱乐部等你
- 美国已成全球最大石油出口国,高油价为何反成其盔甲?
- 超600万公里!中国织出全球最大交通网,我们的生活已被彻底改变
- 多名模特集体控诉世界顶级模特经纪大佬,灌醉性侵,牵扯多名富豪
- 东非大裂谷:世界陆地上最大断裂带,被称为“地球上最长的伤疤”
- 国际足联世界排名更新:中国名次稳定;西班牙第1,阿根廷第2,最大黑马挪威飙升12位到第19
- 知道吗?世界上的5大洋10大海指哪些
热门阅读
-
 1
1
-
 2
泷泽萝拉作品,光看一眼就让人欲罢不能 07-14
2
泷泽萝拉作品,光看一眼就让人欲罢不能 07-14 -
 3
欧美r级片尺度之大,绝对让你欢乐多多快乐无限 07-14
3
欧美r级片尺度之大,绝对让你欢乐多多快乐无限 07-14 -
 4
高岗事件真相令人震惊 究竟有何隐秘内幕 07-14
4
高岗事件真相令人震惊 究竟有何隐秘内幕 07-14 -
 5
北京大裤衩 也就是中央电视台总部大楼 10-24
5
北京大裤衩 也就是中央电视台总部大楼 10-24 -
 6
江户四十八手 看一看可以年轻十岁 11-01
6
江户四十八手 看一看可以年轻十岁 11-01 -
 7
柳州莫菁视频流出,最终判定是男友所为触及法律底线 11-14
7
柳州莫菁视频流出,最终判定是男友所为触及法律底线 11-14 -
 8
揭秘翁帆怀孕真相 杨振宁和翁帆的孩子 11-15
8
揭秘翁帆怀孕真相 杨振宁和翁帆的孩子 11-15