永别了,人类冠军,AI横扫天文奥赛,GPT-5得分远超金牌选手2.7倍
国际奥赛又一块金牌,被AI夺下了!在国际天文与天体物理奥赛(IOAA)中,GPT-5和Gemini 2.5 Pro完胜人类选手,在理论和数据分析测试中,拿下了最高分。
IMO、IOI之后,AI再夺奥赛冠军。
刚刚,在国际天文与天体物理奥林匹克竞赛测试中,GPT-5和Gemini 2.5 Pro达到金牌水平!
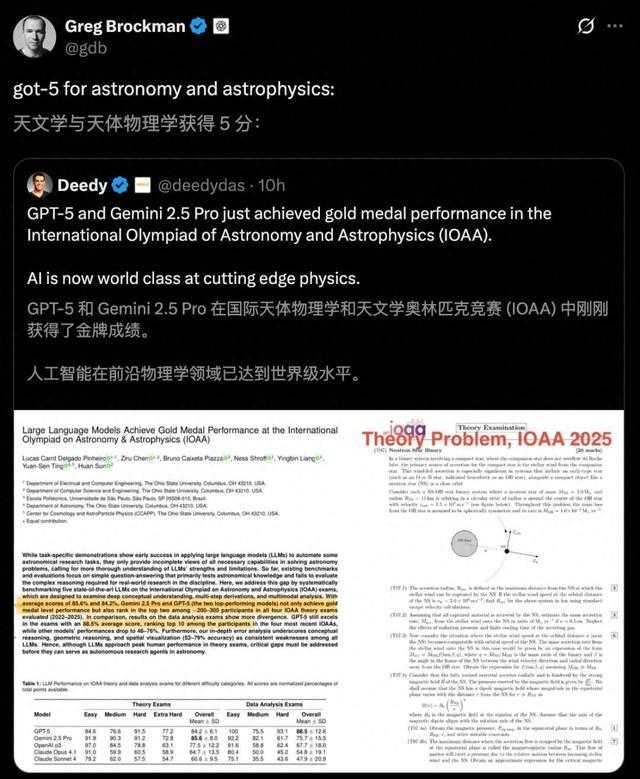
在理论考试上,Gemini 2.5 Pro总体得分85.6%,GPT-5总体得分84.2%;
在数据分析考试中:GPT-5总体得分88.5%,Gemini 2.5 Pro总体得分75.7%。
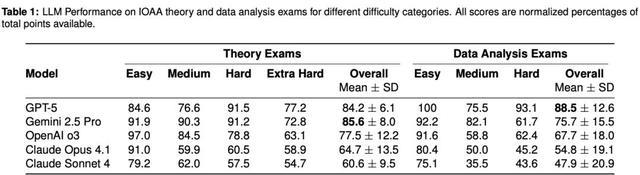
在IOAA 2025上,AI的表现惊人,其水平竟高达人类金牌得主的2.7倍!
我们正在见证AI大爆炸——今日之奥赛,明日之科学,AI将推动全部学科的进展。
AI再夺IOAA金牌,见证历史!
国际天文与天体物理奥林匹克竞赛(International Olympiad on Astronomy and Astrophysics,IOAA),由国际天文学联合会主办的全球性青少年天文赛事,是国际科学奥林匹克竞赛之一、全球天文科学领域最具有影响力的赛事之一。

竞赛包含理论测试、实测数据分析、天文观测三大核心环节,并设置团队协作项目以增强国际互动。
这些竞赛试题极为严苛,通常只有全球最顶尖的学生才能解答。
它们需要深厚的概念理解能力、冗长的公式推导,以及需耗时数小时才能完成的天体物理学难题。
如今人工智能不仅能够通过考试,更在全球200至300名人类参赛者中跻身前两名。GPT-5平均得分85.6%,Gemini 2.5 Pro获得84.2%——两者均达到金牌标准。
我们已正式进入AI能与物理学和天文学领域最聪颖的年轻头脑抗衡的时代。
这并非琐碎知识的比拼,而是关于中子星、吸积流、磁场和轨道力学的尖端推理。

人工智能不再只是生成文字,它开始思考宇宙的奥秘。
但报告指出,在空间和时间推理方面,目前所有LLM都存在困难。
因此,ASI之路还很长,仍需上下求索。
五大LLM打擂台,几乎全线摘金
最新研究由俄亥俄州立大学团队完成,重点考察了五大顶尖LLM,在天文和物理学方面的实力。

论文地址:
https://arxiv.org/pdf/2510.05016
为此,他们选取了最近四届IOAA理论考试(2022-2025)。之所以选择IOAA来衡量,原因有三:
现有的基准,如AstroMLab、AstroBench等仅通过选择、简答和判断题来考察LLM的天文学知识;
IOAA题目具备全面性,涵盖了宇宙学、球面三角学、恒星天体物理学、天体力学、光度学和仪器学等广泛的主题;
IOAA将理论物理、观测约束和真实天文数据与数学计算融为一体,为评估LLM的科学问题解决能力提供了一个独特的视角

除了以上提到的Gemini 2.5 Pro和GPT-5,团队还让o3、Claude-4.1-Opus、Claude-4-Sonnet等三款模型共同参战。
它们均是在AstroBench表现最强模型之一,而且还具备了多模态能力。
所有模型的输出,由两名IOAA专家遵循官方评分细则进行独立评分。
实验结果:理论考试
在理论考试中,GPT-5和Gemini 2.5 Pro表现最佳,比分高出其他模型约7到25个百分点。
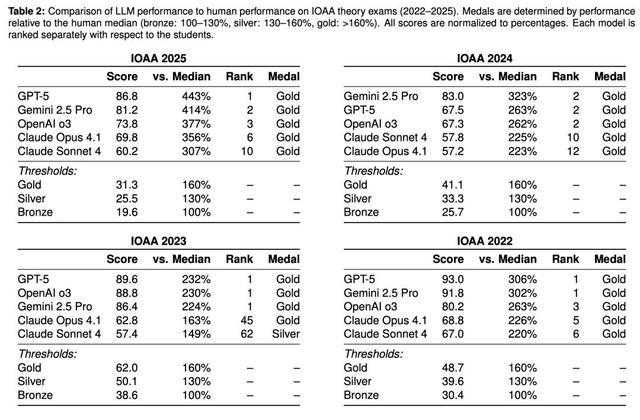
具体来说(见下表2),GPT-5在2022年(93.0%)、2023年(89.6%)和2025年(86.8%)取得最高分,而Gemini 2.5 Pro在2024年以83.0%夺冠。
在以几何题为主的2024年试卷上,Gemini 2.5 Pro凭借更强的几何问题解决能力,取得了最佳总体成绩(85.6%);GPT-5在该年未能获得高分。
尽管总体表现强劲,GPT-5在难题上的表现优于简单与中等难度题。
对此,研究人员分析出三点可能的原因。
第一,各难度级别的问题数量较少,容易产生表现波动:简单题仅10道,中等题11道,分别约占总分185分和151分(总分为所有类别的1200分)。因此,少数错误就能显著影响模型在该难度段的得分。
第二,GPT-5在2024年试卷上出现了若干重大失误,这些失误多来自涉及几何与空间可视化的题目。
第三,GPT-5有时在天体物理学题上出错。例如,2024年试卷的第9题(被归为简单题)中,GPT-5因概念性错误与计算错误共损失18分——这一题的错误几乎占简单题可得分数的10%。
基于这些原因,研究人员认为,GPT-5在简单题和中等难度题上表现不佳,并非由于明显的不当行为;更大的数据集,可能会减少偶尔错误的影响,并在难度类别之间实现更平衡的分布。
其他模型也具有竞争力:OpenAI o3总体得分77.5%,比Claude系列高出约13–17个百分点;其中Claude Opus 4.1得分64.7%,Claude Sonnet 4得分60.6%。
此外,这些模型的表现会随着题目难度的增加而下降。
尽管三者在某些简单基准(如带多项选择题的AstroMLab)上的表现相近并且积极,这次评估仍揭示了显著的性能差距。
这提示需要更全面地评估天文学领域的LLM,以测试其在问题解决能力上超越单纯知识回忆的能力。
实验结果:数据分析考试
相比之下,数据分析考试更能揭示模型在细节与多模态任务上的能力与局限(见表1)。
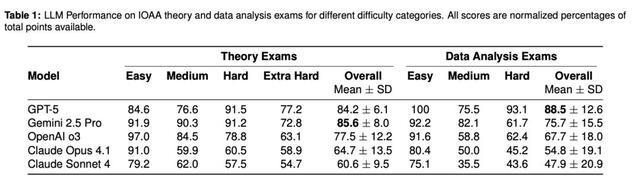
GPT-5在数据分析部分表现出色,总体得分88.5%,高于其理论考试成绩(84.2%)。
这一提升与其他模型形成鲜明对比:其他模型从理论到数据分析通常下降约10–15个百分点。
造成这种差异的原因在于:
数据分析考试,高度依赖图表解读与数据可视化;
GPT-5更强的多模态能力解释了其优势。
为进一步推动天体物理领域中大语言模型的发展,研究人员呼吁开发更具生态效度的多模态天文数据分析基准,作为对模型更全面评估的补充。
媲美顶尖人类选手
AI实力却是很强,那么它们是否可与人类一较高下?
为此,研究人员根据IOAA的评分标准,将模型得分与人类参赛者进行比较。
IOAA奖牌的评定基于参赛者总分(理论+数据分析+观测考试之和),相对于中位数的表现——
铜牌为中位数的100%–130%,银牌为130%–160%,金牌则为160%以上。
注:本次评估不包含观测考试,作者分别为理论考试和数据分析考试计算了相应的奖牌门槛。
在理论考试中,几乎所有LLM表现堪称「学霸级别」,得分轻松跨过金牌线!
唯一例外的是Claude Sonnet 4,在2023 IOAA中拿下了银牌。
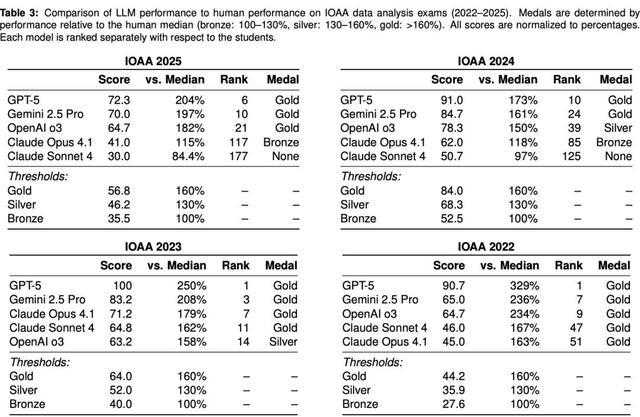
总体来看,这些模型不仅达到了金牌水平,甚至与全球TOP 200-300顶尖人类参赛者中,名列前茅。
在2022、2024和2025年的考试中,各模型均稳定排名前12。
更令人震撼的是,在2022、2023、2025理论考试中,GPT-5均超过了当年的IOAA最佳学生,堪称「学神」!
Gemini 2.5 Pro在2022和2023年,同样力压最佳人类选手。
OpenAI o3在2023年考试中,亦超过了最佳学生。
Claude Opus 4.1与Claude Sonnet 4在2023年虽未能与顶尖学生相媲美,但它们的得分仍明显高于中位数,分别位列第45和第62。
LLM偶有失败,仍需上下求索
为了更深入地了解LLM在天文问题解决中的长处和短处,根据IOAA理论考试中不同类型的问题,研究人员对LLM的表现进行了分析。
根据评分团队专家的评估,这次研究将理论问题分为两类:
• 第一类(几何/空间):涉及空间可视化的问题,包括天球、球面三角学、时间计量系统和向量几何。
• 第二类(物理/数学):主要涉及宇宙学和天体物理计算以及天体力学,不要求几何可视化。
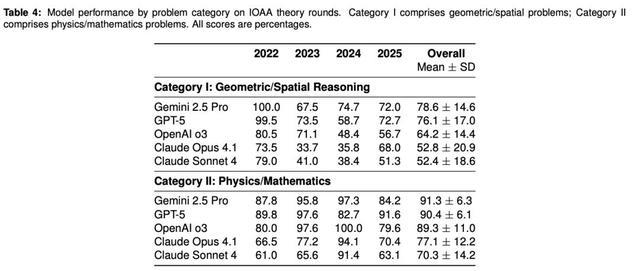
尽管这个分类(上表4)并不全面,但它清楚地揭示了系统性差异:
模型在第二类物理问题上的得分较高(67–91%),而在第一类几何问题上的得分明显较低(49–78%),两者相差15–26个百分点。
这种差异在2024年的考试中尤为显著,当时第一类问题占据了主导地位——只有Gemini 2.5 Pro保持了相对较高的性能(74.7%),而其他模型的性能则下降到了35–59%。
按年份、难度和类别划分的IOAA理论问题分析
即便如此,Gemini在第一类问题上的性能也比第二类问题(91.3%)低12.7个百分点。
为什么LLM在几何问题上表现不佳?
通过定性分析,研究人员发现除了计算错误外,LLM还面临一些根本性的问题。
首先,模型在概念上难以理解球面三角学。例如,GPT-5会写出违反基本几何原理的球面三角学方程,并尝试进行与大圆几何不一致的角度计算。
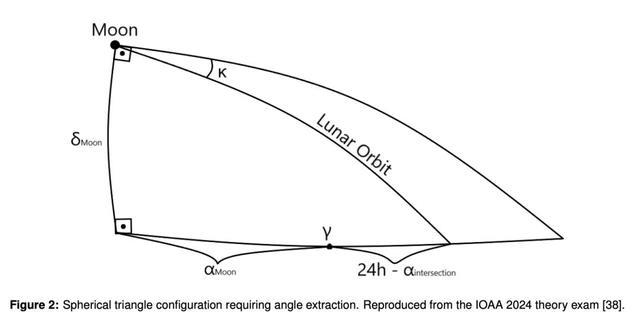
此外,所有模型在时间计量系统上都表现出混淆,无法正确区分热带年和恒星年。一些解答甚至隐含地将日历年和热带年视为相同。
最后,目前的LLM只能用自然语言进行推理,无法在思考时进行空间表示的视觉化或草图绘制,这与人类参与者相比处于天然劣势。
这些失败模式表明,多模态推理,特别是空间和时间的,是提升LLM在天文问题解决能力的重要未来方向。
除了定性分析外,研究人员还将所有错误定量地分为八个类别,以系统地识别大语言模型的弱点。
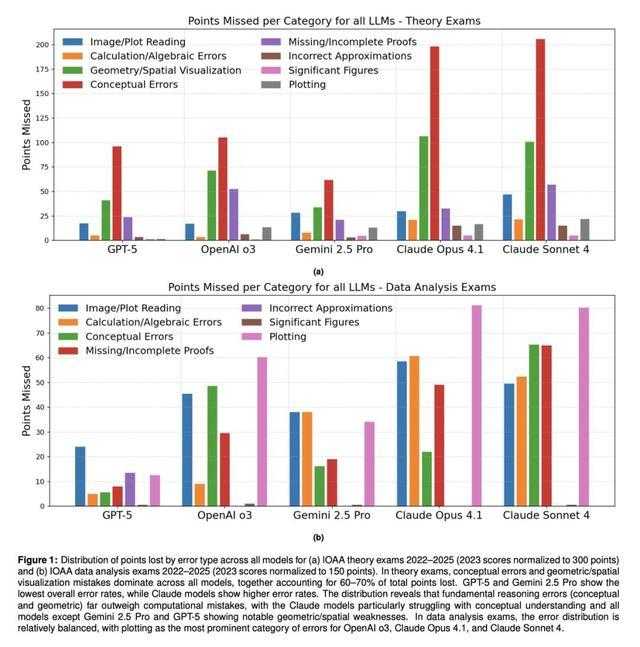
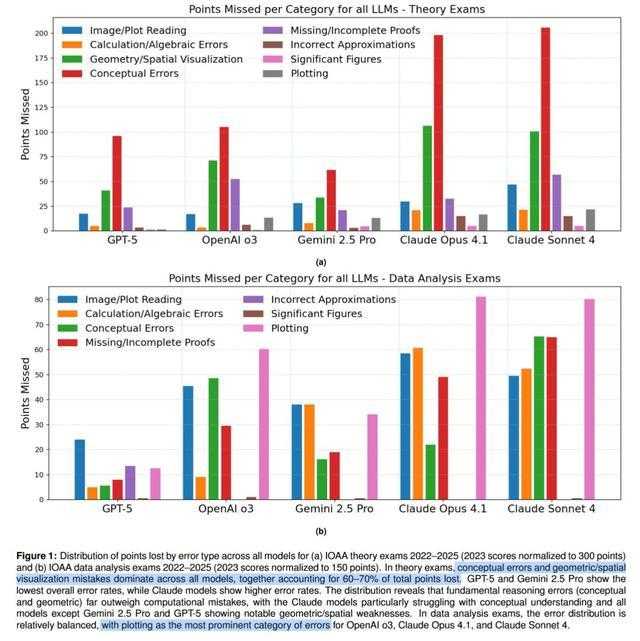
图1:所有模型在IOAA理论考试(2022-2025年,其中2023年得分标准化为300分)和数据分析考试(2022-2025年,其中2023年得分标准化为150分)中按错误类型丢失的分数分布。
在理论考试中,概念性错误和几何/空间可视化错误在所有模型中占主导地位,共同占去了60-70%的总失分。GPT-5和Gemini 2.5 Pro显示出最低的整体错误率,而Claude模型的错误率较高。
分布显示,基本的推理错误(概念性和几何性)远远超过了计算错误,特别是Claude模型在概念理解上存在困难,除了Gemini 2.5 Pro和GPT-5之外的所有模型都显示出明显的几何/空间弱点。
在数据分析考试中,错误分布相对平衡,绘图「Plotting」是OpenAI o3、Claude Opus 4.1和Claude Sonnet 4中最突出的错误类别。
在所有模型中,概念性错误最为普遍,反映了实现深度物理理解的难点。
与国际数学奥赛(IMO)等纯数学竞赛不同,物理和天体物理奥林匹克竞赛要求将数学形式与物理直觉相结合,在评估科学推理能力方面别具价值。由于这些错误触及理解的核心,它们通常出现在所有类型的问题中,并导致严重的扣分。
第二大错误来源是几何或空间推理。这些错误完全集中在第一类问题中,这进一步证实了空间推理是大语言模型的一个关键弱点。
模型经常无法可视化三维配置,错误识别天体坐标之间的角度,或在球面几何中错误地应用向量运算。
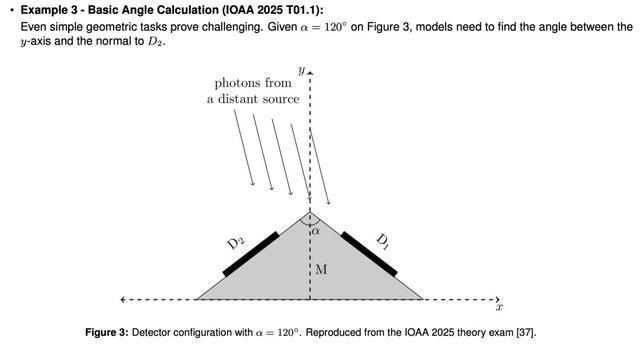
这些失败甚至发生在几何问题被清晰地用文字描述的情况下。这在第一类问题中占大多数,表明这些限制不仅在于多模态,还在于LLM在处理与空间推理相关任务时的基本能力。
此外,天文学奥林匹克竞赛非常重视近似和数量级推理,因为天文学涉及的尺度非常庞大。
尽管模型通常能够合理地处理近似问题,但特定的失败案例突显了物理直觉方面的差距。
特别是,模型常常在数量级上错误判断天文学距离,或者在问题约束下未能识别近似无效的情况。
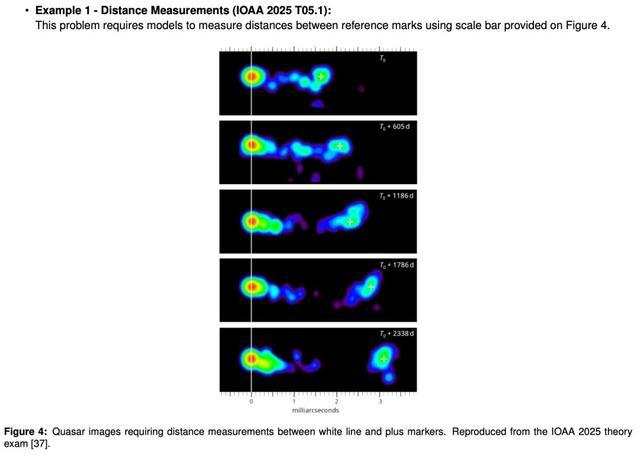
在解释图表和图像方面的错误,尽管仅限于有视觉输入的问题,但也具有相当的权重。
这种模式与已知的LLM的多模态限制一致,比如记录的图表理解失败,也符合莫拉维克悖论:
对人类来说简单的任务,如视觉解释,对人工智能来说仍然困难。
最后,当模型在没有展示中间步骤的情况下直接给出最终表达式时,会观察到缺失或不完整的推导,这表明数学推理的透明度存在限制。
其他类别,包括计算错误、符号精度和近似错误,导致的扣分较少,表明模型具有相当不错的计算能力。
数据分析考试中的失败模式
与理论考试不同,数据分析考试的错误分布(见图1b)在多个类别中相对较为均匀。
正如预期的那样,绘图和图表及图像阅读在数据分析考试中也会导致扣分。
能力较弱的三个模型,OpenAI o3、Claude Opus 4.1和Claude Sonnet 4,主要的错误类别是绘图,而GPT-5和Gemini 2.5 Pro的主要扣分来源是图像和图表阅读。
计算错误也在数据分析考试中导致了相当一部分的扣分。
对于Gemini 2.5 Pro,计算错误甚至与图像和图表阅读一样,是另一个主要的错误来源。这是因为许多数据分析问题涉及长表格,并且需要计算多个值以生成图表。
值得注意的是,理论考试中主要的扣分原因——概念性错误和几何错误——在数据分析考试中并不突出。
尽管概念性错误可能出现在任何问题中,并且仍然会导致大多数模型在数据分析考试中扣分,但对图表阅读和绘图任务的强烈关注使得其他类型的错误更有可能发生。
参考资料:
https://x.com/gdb/status/1977052555898482727
https://x.com/VraserX/status/1977039338136322463
https://x.com/ai_for_success/status/1977066532628054401
本文来自微信公众号“新智元”,作者:新智元,编辑:KingHZ 桃子,36氪经授权发布。
大家都在看
-

郭守敬:元代科学天花板,领先世界数百年的“六边形战士” 在中国古代科学史上,有这样一个人:他编的历法,比西方早了300年;他修的水利,至今还在发挥作用;他造的天文仪器,精度领先世界;他测绘的疆域,比欧洲人早了200年。但就是这样一位科学巨匠,在我们的历史课本里, ... 天文之最07-31
-

詹姆斯韦布望远镜发现著名恒星系统隐藏巨行星 这幅艺术家概念图展示了绘架座β系统,右侧是已发现的巨型系外行星绘架座βd。在该系统已知的三颗系外行星中,它拥有最宽的轨道。图片来源:美国国家航空航天局(NASA)、欧洲空间局(ESA)、加拿大空间局(CSA)、 ... 天文之最07-31
-

元朝最被低估的旷世奇才!凭一己之力,让中国天文领先世界三百年 说起元朝,多数人的印象只有铁骑西征、疆域辽阔,总觉得这是一个重武轻文、科技落后的朝代。 但很少有人知道,元朝藏着一位碾压时代的全能科学神人,他的成就领先世界数百年,横跨天文、水利、数学、器械制造四大领 ... 天文之最07-31
-

研究发现:木星比太阳年龄还大,它才是太阳系最古老的天体 我们被太阳骗了46亿年,它根本不是太阳系最古老的天体,早在它还没点火的时候,木星就已经长成了引力巨兽,论资排辈,它比太阳还要早一步站稳脚跟。我们从小接受的认知都是:先有太阳诞生,点燃核聚变成为恒星,周围 ... 天文之最07-30
-

《夜航船》解析—卷一·天文部·日月(三十一)—月食五星 月食五星①崇祯十一年②四月己酉夜,荧惑③去月仅七八寸,至晓逆行,尾八度掩于月,丁卯退至尾,初度渐入心宿④。杨嗣昌⑤上疏言:“古今变异,月食五星,史不绝书,然亦观其时。昔汉元帝建武二十三年⑥,月食火星, ... 天文之最07-30
-
“迄今为止最有力的证据”,天文学家拍摄到参宿四伴星图像 参宿四是夜空中最著名、也是冬季夜空中最亮的恒星之一,它位于猎户座,距离地球约650光年。这是一颗已经步入恒星演化末期的红超巨星,亮度呈现周期性变化。 长期以来,天文学家一直怀疑,参宿四很可能拥有一颗伴星, ... 天文之最07-30
-

大思考,盘点过去20年中最重大的20项宇宙发现 人类对浩瀚星空的认知,在过去两个世纪里经历了一场跨越数量级的深刻变革。两百年前,人类甚至无法精准测量一颗恒星距离地球究竟有多远,也不清楚它们由何种物质构成。从十九世纪三十年代首次成功测量恒星视差,到海 ... 天文之最07-30
-

无望远镜观测天花板!第谷·布拉赫,一人撑起近代天文学数据根基 第谷·布拉赫:裸眼观测时代的奇才,以毕生数据铸就《鲁道夫天文表》在望远镜尚未问世的16世纪,天文学长期依靠粗略观测与古典理论推演,星象测算误差巨大,难以支撑严谨的天体研究。丹麦天文学家第谷·布拉赫(1546 ... 天文之最07-30
-

汉代天文档案:2000年前中国已算出一年365.25天?比欧洲早1600年 朋友们,先问你一个特别“降维打击”的问题。你手机里的日历,2024年是闰年,2月有29天。你知道为什么吗?你可能会说:“废话,因为地球绕太阳一圈不是整天数呗,四年凑一天补上。”行,算你有点天文常识。那我再问 ... 天文之最07-30
-

深度长文:宇宙最残酷的真相,或许人类永远找不到外星人! 1950年,著名物理学家费米在一次闲聊中,随口抛出了一个困扰人类科学界七十多年的终极问题:“外星人到底在哪?”就是这一句简单的发问,后来被命名为费米悖论,成为了天文学、生物学、物理学交叉领域最无解的谜题。 ... 天文之最07-27
相关文章
- 大思考,盘点过去20年中最重大的20项宇宙发现
- 无望远镜观测天花板!第谷·布拉赫,一人撑起近代天文学数据根基
- 汉代天文档案:2000年前中国已算出一年365.25天?比欧洲早1600年
- 肉眼观测的天花板!没有望远镜的第谷,奠定近代天文学根基
- 深度长文:宇宙最残酷的真相,或许人类永远找不到外星人!
- 重磅!科学家在宜居带内的类地行星上探测到大气,它距地球49光年
- 商朝人天文、数学、文字样样精通,看完我直接跪了!
- 最古老火星陨石揭示火星早早就失去了水
- 巨蟹座与鬼宿、巨蟹宫:同一片暗星,三套命名体系!
- 科学家发现太阳中银元素的实际含量比科学界普遍认同的高出55%。
- 你只知道她是太阳的妈妈?正史里的羲和,其实是个硬核天文官
- 巡天巨眼 暗宇探秘 —— 南希・格雷斯・罗曼太空望远镜即将启程
- 中国科学院大学天文与空间科学学院、国家天文台副教授人民日报撰文:地球之水哪里来?星际冰图告诉你
- 韦伯望远镜立大功!宇宙最怪套娃现身:外表像恒星,内核是黑洞
- 被课本低估的千古天才!阿基米德到底有多牛?比肩牛顿、高斯
- 一枚SpaceX猎鹰9号火箭将于8月5日撞击月球,地球部分地区可观测
- 詹姆斯韦伯望远镜发现著名恒星系隐藏巨行星
- 邓煜王虹同摘世界顶级数学奖 是什么让顶尖科学家认定“现在是我们基础科研最好的时代”?
- 宇宙中10大奇异恒星,最快恒星每秒跑1200公里,太阳真是平淡无奇
- 天文学家最爱的红矮星,可能是银河系披着羊皮的狼
热门阅读
-
 1
1
-
 2
毕达哥拉斯定理,在科学界中发挥巨大作用 07-14
2
毕达哥拉斯定理,在科学界中发挥巨大作用 07-14 -
 3
3
-
 4
4
-
 5
5
-
 6
6
-
 7
7
-
 8
8