英伟达再破世界纪录,每秒1000 token,刚刚,全球最快Llama 4诞生
英伟达,亲手打破了自己的天花板!刚刚,Blackwell单用户每秒突破了1000个token,在Llama 4 Maverick模型上,再次创下了AI推理的世界纪录。在官博中,团队放出了不少绝密武器。
你以为,AI推理的速度已经够快了?
不,英伟达还能再次颠覆你的想象——就在刚刚,他们用Blackwell创下了AI推理的新纪录。

仅仅采用单节点(8颗Blackwell GPU)的DGX B200服务器,英伟达就实现了Llama 4 Maverick模型每秒单用户生成1000个token(TPS/user)的惊人成绩!

单节点使用8块B200 GPU
这项速度记录,由AI基准测试服务Artificial Analysis独立测量。
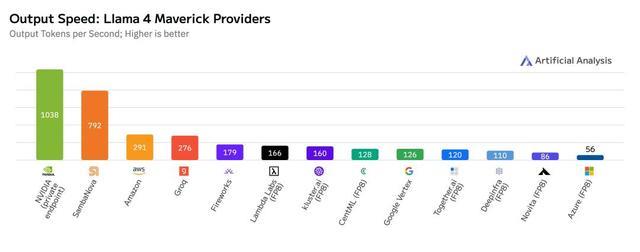
而且,更令人咋舌的是,单台服务器(GB200 NVL72,配备72颗Blackwell GPU)的整体吞吐量,已经达到了72,000 TPS!

GB200 NVL72液冷机架原型机
这场速度革命的幕后,是一整套精心布局的技术组合拳——
使用TensorRT-LLM优化框架和EAGLE-3架构训练推测解码草稿模型;
在GEMM、MoE及Attention计算中全面应用FP8数据格式,有效缩小模型体积并提高计算效率;
应用CUDA内核优化技术(如空间分区、GEMM权重重排、Attention内核并行优化、程序化依赖启动(PDL)等);
运算融合(如FC13+SwiGLU、FC_QKV+attn_scaling、AllReduce+RMSnorm融合)。
由此,Blackwell的性能潜力彻底被点燃,一举实现了4倍加速,直接把之前的最强Blackwell基线甩在身后!
迄今测试过最快Maverick实现
这次优化措施在保持响应准确度的同时,显著提升了模型性能。
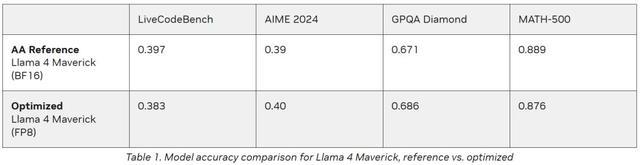
英伟达针对GEMM(通用矩阵乘法)、MoE(混合专家模型)及Attention(注意力)运算运用了FP8数据类型,旨在减小模型体积,并充分利用Blackwell Tensor Core技术所带来的高FP8吞吐量优势。
如下表所示,采用FP8数据格式后,模型在多项评估指标上的准确度可与Artificial Analysis采用BF16数据格式(进行测试)所达到的准确度相媲美:
为何减少延迟至关重要?
大部分用生成式AI的场景,都要在吞吐量(throughput)和延迟(latency)之间找一个平衡点,好让很多用户同时使用时,都能有个「还不错」的体验。
但是,有些关键场景,比如要迅速做出重要决策的时候,「响应速度」就变得特别重要,哪怕一点延迟都可能带来严重后果。
无论你想要的是同时处理尽可能多的请求,还是希望既能处理很多请求、响应又比较快,还是只想最快地服务单个用户(即最小化单个用户的延迟),Blackwell的硬件都是最佳选择。
下图概述了英伟达在推理过程中应用的内核优化和融合(以红色虚线框标示)。
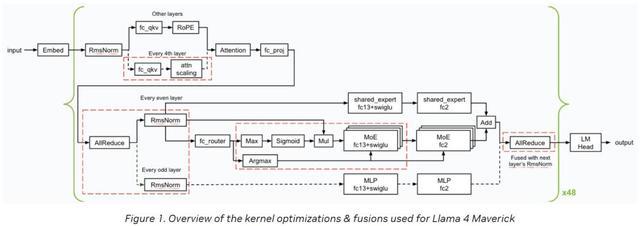
英伟达实现了若干低延迟GEMM内核,并应用了各种内核融合(如FC13+SwiGLU、FC_QKV+attn_scaling以及AllReduce+RMSnorm),从而使Blackwell GPU在最小延迟场景下表现出色。
CUDA内核优化与融合
在内核优化与融合方面,英伟达采用了以下几项关键技术:
空间分区与高效内存加载
利用空间划分(也称为warp专业化)并设计GEMM内核,可以高效的方式从内存中加载数据,从而最大限度地利用NVIDIA DGX所提供的巨大内存带宽——总计64TB/s。
GEMM权重重排
将GEMM权重以一种优化的swizzled格式进行重排。
由此可以确保在使用Blackwell第五代Tensor Core完成矩阵乘法计算后,从Tensor内存加载计算结果时能够获得更理想的数据布局。
Attention内核并行优化
通过沿K和V张量的序列长度维度对计算进行划分,优化了Attention内核的性能,使得计算任务能够在多个CUDA线程块上并行执行。
此外,还利用分布式共享内存机制,在同一线程块集群内的不同线程块之间高效地进行结果规约,从而避免了访问全局内存的需要。
运算融合
通过启用不同运算之间的融合,来减少内核执行间的开销以及内存加载/存储的次数。
例如,将AllReduce运算与紧随其后的RMSNorm运算及量化(Quantize)运算融合成单一的CUDA内核,以及将SwiGLU运算与其前置的GEMM运算进行融合。
程序化依赖启动(PDL)
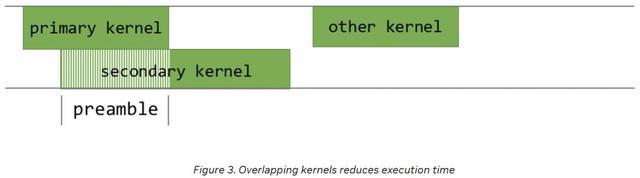
程序化依赖启动(PDL)是一项CUDA功能,它能够减少同一CUDA流上两个连续CUDA内核执行之间的GPU空闲时间,甚至允许这两个内核部分重叠执行。
默认情况下,当多个内核在同一个CUDA流上启动时,第二个内核必须等待第一个内核执行完毕后才能开始。
这种机制会导致两个主要的性能问题:
其一,两个连续的内核执行之间会产生微小的间隙(如下图所示),在此期间GPU处于闲置状态。
其二,当第一个内核的执行接近尾声时,它可能仍会占用一部分流式多处理器(SM)来完成剩余的CUDA块计算,这使得GPU上的其他SM处于空闲,从而导致GPU整体计算能力的利用率不足。

通过在CUDA中运用程序化依赖启动API,英伟达允许次级内核(secondary kernel)在主内核(primary kernel)仍在运行时就开始执行。
在初始准备阶段(preamble period),次级内核可以执行那些不依赖于主内核执行的计算任务,并加载相应的数据。
这不仅消除了两个连续内核之间的执行间隙,也显著提升了GPU的利用率;因为当主内核仅占用GPU上的部分SM时,其余空闲的SM便可以开始运行次级内核。
推测解码
推测解码(Speculative Decoding)是一种广受欢迎的技术,用于在不牺牲生成文本质量的前提下,加速LLM的推理速度。
该技术通过一个规模更小、速度更快的「草稿」模型来预测一个推测token序列,然后由规模更大(通常也更慢)的LLM并行验证这些token。
其加速效果源于:在目标模型的一次迭代中,有机会生成多个token,代价则是草稿模型带来的一些额外开销。
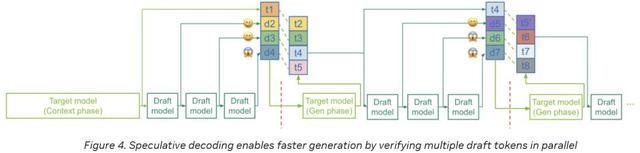
端到端的工作流
首先,在目标模型完成上下文阶段(此阶段亦会生成token t1)之后,草稿模型会迅速生成一连串潜在的token(例如d2-d4)。
随后,目标模型进入生成阶段,在这一阶段,它会针对整个草稿序列,一次性地并行验证(或生成)每个位置的下一个token。
如图所示,如果草稿token与目标模型自身将要生成的token相匹配,目标模型便可能「接受」其中的若干token(如d2、d3),同时「拒绝」其他的token(如d4)。
这个循环不断重复:被接受的token得以保留;若发生拒绝(例如,在d4被拒绝后),目标模型会提供正确的下一个token(如t4);然后,草稿模型会生成一个新的推测序列(例如d5-d7)。
通过并行验证多个token——而不是依赖(速度较慢的)目标模型逐个生成它们——并充分利用草稿模型的快速推测能力,系统能够实现显著的速度提升,尤其是当草稿模型的预测准确率较高时。
「接受长度(AL)」定义为在单次验证步骤中,平均能够成功生成的token数量。
AL值越高,加速效果越显著。
对此,英伟达采用了一种基于EAGLE3的架构作为其推测解码方法,主要通过调整推测层中前馈网络(FFN)的大小来优化接受长度(AL)。
在推理过程中,需要在目标模型的前向传播阶段记录低、中、高三个层级的特征(即初始、中间及末端解码层输出的隐藏状态)。
之后,再将这些隐藏状态与token嵌入相结合,并将结果输入到推测层。该推测层随后以自回归方式生成一个草稿token序列,供目标模型进行并行验证。
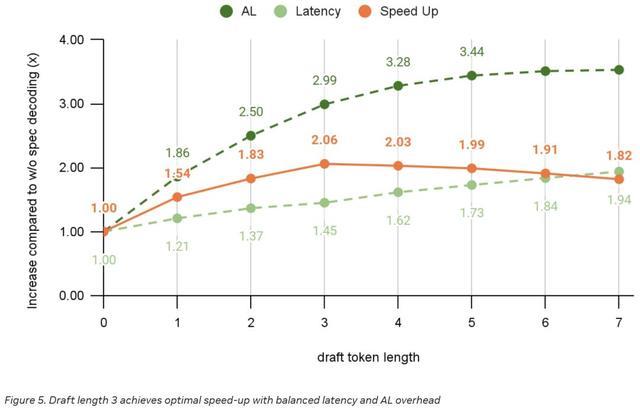
推测层的开销虽然不大,但也不可忽视。因此,关键的挑战在于如何在草稿长度与端到端加速效果之间取得理想的平衡。
草稿长度越长,AL通常也越高,但相应地,运行草稿模型所产生的额外成本也会增加。根据英伟达在下方实验中展示的结果,当草稿长度设置为3时,可获得最佳的加速效果。
通过CUDA Graph和重叠调度器减少主机端开销
推测解码的另一个挑战在于减少主模型与草稿模型之间的通信和同步开销。
如果英伟达将采样/验证逻辑置于主机端,便会在主机与设备之间引入额外的同步点,进而破坏CUDA Graph的完整性。
因此,英伟达选择将验证逻辑保留在设备端,从而能够将目标模型的前向传播、验证逻辑以及草稿模型的前向传播都整合到同一个CUDA Graph中。
此外,英伟达还启用了TensorRT-LLM的重叠调度器,以进一步让当前迭代的模型前向传播与下一次迭代的输入准备及CUDA Graph启动过程实现重叠。
使用torch.compile优化草稿模型层
由于验证逻辑是采用Torch原生操作在设备端实现的,这导致英伟达最终生成了大量细小的Torch原生内核。
手动融合这些内核不仅复杂,且容易出错。
为此,英伟达采用torch.compile,借助OpenAI Triton的能力来自动完成这部分内核的融合,并生成最优化的版本。
这一举措帮助英伟达将草稿模型的开销从25%成功降低到了18%(当草稿长度为3时)。
总结
总的来说,这一创世界纪录的速度,是强大Blackwell架构、自CUDA层面起直至上层应用的深度软件优化,以及英伟达量身定制的推测解码实现所带来的显著加速三者结合的成果,它直接响应了下一代AI交互应用对低延迟的迫切需求。
正如英伟达所展示的那样,这些技术进步确保了即便是超大规模模型,也能够提供足够的处理速度和响应能力,以支持无缝的实时用户体验和复杂的AI智能体部署场景。
作者介绍
Yilin Fan

Yilin Fan是英伟达的高级深度学习工程师,专注于TensorRT/TensorRT-LLM的性能。
他拥有卡内基梅隆大学的软件工程硕士学位和北京航空航天大学的学士学位。
在加入英伟达之前,他曾在小马智行工作,负责优化与部署自动驾驶汽车上的深度学习模型。
Po-Han Huang

Po-Han Huang是英伟达的深度学习软件工程师。
在过去六年多的时间里,他一直致力于通过TensorRT和CUDA优化来加速已训练深度神经网络模型的推理。
他拥有伊利诺伊大学厄巴纳-香槟分校的电子与计算机工程硕士学位,专业知识涵盖深度学习加速、计算机视觉和GPU架构。
Ben Hamm

Ben Hamm是英伟达的技术产品经理,专注于LLM推理性能与优化。
此前,他曾在亚马逊担任产品经理,负责Alexa的唤醒词检测机器学习栈。之后加入OctoAI并担任LLM托管服务的产品经理。随着公司被收购,他也跟着一起来到了英伟达。
有趣的是,作为一名计算机视觉的爱好者,他甚至还发明了一款AI驱动的猫门。
参考资料:
https://developer.nvidia.com/blog/blackwell-breaks-the-1000-tps-user-barrier-with-metas-llama-4-maverick/
本文来自微信公众号“新智元”,作者:新智元,36氪经授权发布。
大家都在看
-

爆了!全球最大!中国一周连破3项世界纪录,彻底刷屏 谁也没想到,短短7天,中国直接甩出3个“全球第一”!从海上光伏到超级巨轮,再到深山大桥,每一项都刷新世界纪录,每一个突破都硬气到骨子里!外媒集体眼红,网友直呼:这就是中国速度,中国实力!第一个炸裂突破: ... 世界记录06-15
-

打破基因偏见!黄种人守住的田径世界纪录,每一项都是封神 长久以来,田径赛场都被大众固有认知绑架:短跑看黑人、长跑看非洲、欧美垄断技术项目,黄种人只配陪跑、难破极限。但很多人不知道,目前世界田联官方认证的田径世界纪录中,有多项至今牢牢握在黄种人手中,几十年无 ... 世界记录06-14
-

四届世界杯,14项吉尼斯纪录,夏奇拉为何是世界杯恒久标志? 2026年6月11日,墨西哥城阿兹特克体育场,49岁的夏奇拉身穿金色战袍,站在世界杯开幕式的舞台上。她做的第一件事不是唱歌——而是标志性的抖臀。几万人的看台瞬间爆表。这距离她第一次登上世界杯舞台,已经过去了整 ... 世界记录06-14
-

长8米重达20余斤!22岁女大学生玩转非遗中幡 30秒19圈创下吉尼斯世界纪录 6月12日,文化和自然遗产日前夕,红星新闻记者从吉尼斯世界纪录获悉,天津师范大学22岁体育专业学生姜琦凭借精湛技艺,以30秒内完成19圈中幡绕身旋转的成绩,成功创下“30秒内中幡围绕身体旋转圈数最多”吉尼斯世界 ... 世界记录06-13
-

12秒75,美国选手撒普打破男子110米栏世界纪录;此前纪录是美国选手梅里特创造的12秒80,刘翔也曾是该项目的世界纪录保持者 美国选手撒普10日在美国大学体育协会(NCAA)田径锦标赛中跑出12秒75,打破尘封近14年的男子110米栏世界纪录。当天比赛在田径项目胜地——俄勒冈州的尤金举行。20岁的撒普是在半决赛中跑出这一成绩的,他在前三栏后 ... 世界记录06-12
-

12秒75,美国18岁新星萨普打破尘封14年的110米栏世界纪录;此前纪录系梅里特在2012年创造,其跑出12秒80终结刘翔保持6年的12秒88世界纪录 据北青体育:北京时间6月10日,在美国NCAA全美大学生一级联赛室外田径锦标赛男子110米栏半决赛中,奥本大学学生贾科布·萨普跑出12秒75的好成绩,一举打破由梅里特保持14年的男子110米栏世界纪录。本次打破纪录的萨 ... 世界记录06-12
-

94岁香港艺人“修哥”红磡演唱会,近5小时45首歌,成功挑战吉尼斯世界纪录,刘德华、张学友、陈奕迅、杨千嬅等到场支持 6月7日,94岁香港艺人“修哥”胡枫在香港体育馆(俗称红磡体育馆、简称红馆)举行“修哥九五至尊无限枫骚演唱会”,演唱会尾声正式宣布胡枫以94岁零140天成功挑战吉尼斯世界纪录,成为“举办演唱会最年长的华语艺人 ... 世界记录06-10
-

港媒:94岁胡枫举办演唱会破吉尼斯世界纪录,刘德华、张学友等到场支持 【环球网报道】据香港星岛头条网6月8日报道,94岁香港艺人“修哥”胡枫7日在香港体育馆(俗称红磡体育馆、简称红馆)举行“修哥九五至尊无限枫骚演唱会”,演唱会尾声正式宣布胡枫以94岁零140天成功挑战吉尼斯世界纪 ... 世界记录06-10
-

创多项世界纪录!世界最大海上换流站完成海上浮托安装 海上风电开发面临高盐雾、高湿度、强风浪、高腐蚀的极端严苛海洋工况,对设备设计、制造、运维提出了极高要求。“海风之心”海上换流站创新采用国内首创模块化、集约化设计,攻克多项海上风电核心技术瓶颈,创多项世 ... 世界记录06-06
-

再创吉尼斯称号!远程星智T9M以醇电硬核实力重构城际运输 2026年6月3日,远程星智T9M甲醇电动轻卡完成“驾驶混合动力厢式轻卡单次满醇满电行驶最远距离”吉尼斯世界纪录™挑战,从杭州远程总部出发,跨越四省直达北京八达岭长城,全程零补能,实现超1699公里极限续航。本次 ... 世界记录06-04
相关文章
- 美国选手撒普打破男子110米栏世界纪录
- 12秒75!美国选手撒普打破尘封近14年的男子110米栏世界纪录
- 大不是目的:今麦郎获吉尼斯世界纪录认证背后的慢功夫
- 94岁香港艺人“修哥”红磡演唱会,近5小时45首歌,成功挑战吉尼斯世界纪录,刘德华、张学友、陈奕迅、杨千嬅等到场支持
- 港媒:94岁胡枫举办演唱会破吉尼斯世界纪录,刘德华、张学友等到场支持
- 创多项世界纪录!世界最大海上换流站完成海上浮托安装
- 远程星智T吉尼斯世界纪录™称号挑战成功 单次满醇满电行驶最远距离超1699公里
- 再创吉尼斯称号!远程星智T9M以醇电硬核实力重构城际运输
- 铸牢中华民族共同体意识 健行吉尼斯展风采 五育并举向未来
- 中国再破世界纪录!全世界卡了几十年的死局,被中国一招破解
- 4秒54!赵一程战胜12天前刷新世界纪录的自己(名场面的背后)
- 一个月内三破世界纪录,光伏龙头全面开启BC竞速赛
- 解锁少年无限可能!校园吉尼斯,让优秀不止一种模样
- 一秒能爬三米多高!成体学子龙见国联手队友,打破世界纪录
- 太牛了!破世界纪录!福州运动员苏连博凡夺金
- 35中!福州苏连博凡破世界纪录夺金!
- 中国选手苏连博凡创造男子25米手枪速射世界纪录
- 吉尼斯“百万宣言”挑战全球发布,南京爱尔熊娟主任邀市民携手共创世界纪录
- 18岁严子怡,71米74!“以后可以畅想一下世界纪录了”
- 苏州企业,打破三项吉尼斯世界纪录!
热门阅读
-
 1
世界上最大的男性生殖器,奇人的丁丁长度达34厘米 07-10
1
世界上最大的男性生殖器,奇人的丁丁长度达34厘米 07-10 -
 2
十种最舒服的安乐死,千万不要尝试哦! 07-11
2
十种最舒服的安乐死,千万不要尝试哦! 07-11 -
 3
陈冠希张柏芝艳照门图片曝光,堪比激情大片(高清) 04-26
3
陈冠希张柏芝艳照门图片曝光,堪比激情大片(高清) 04-26 -
 4
4
-
 5
巩新亮整容前后差异大 网友直呼惨不忍睹 05-05
5
巩新亮整容前后差异大 网友直呼惨不忍睹 05-05 -
 6
张柏芝私人相册照片流出,尺度大的惊人(艳照门图) 05-06
6
张柏芝私人相册照片流出,尺度大的惊人(艳照门图) 05-06 -
 7
美国史上最惨不忍睹的分尸案,黑色大丽花惨案 04-25
7
美国史上最惨不忍睹的分尸案,黑色大丽花惨案 04-25 -
 8
8